Transactions
Transactions provide simple systematic solutions for the construction of distributed applications which manage replicated data and must deal with concurrent requests and failure. A transaction is a fundamental unit of interaction between client and server processes which encapsulates a sequence of operations to satisfy the properties of atomicity, consistency, isolation and durability (ACID). A transaction is, from the client's point of view (though in reality composed of a number of operations), a single step which transforms the server state from one consistent state to another. A transaction appears to occur indivisibly with respect to failures and the activity of other concurrent transactions. Transactions that complete successfully are said to commit, those that fail (and appear not to have happened at all) are said to abort.
Systems that support atomic transactions must satisfy three primary requirements:-
Each transaction must be recoverable, that is, when a client or server halts unexpectedly, the changes to the server state must be completed or returned to a state where the effect is the same as if the transaction never started. This is the atomicity property.
The concurrent execution of a number of transactions must be serially equivalent in that the effect on server state is the same as if the transactions occurred in some arbitrary order. This is the isolation property. In other words, partial results of an incomplete transaction are not visible to other transactions before that transaction is committed.
In addition, transactions must have durability or permanence, which means that the effect of committed transactions are very likely to survive subsequent failures. This is achieved by storing server state and logging transaction details on stable and non-volatile storage.
The consistency property of transactions is dependent on the operations performed by the transactions themselves and is not as such, a responsibility of a transaction mechanism. The series of operations making up a transaction in the application should not violate the consistency of the data.
The ACID properties of transactions allow applications programmers to forget about all the possible ways that transactions could interleave, or all the possible states that could result from failure in the middle of some transaction. To prove correctness of the application, it is enough to check that the initial state of the data is consistent and that each transaction, when run alone, preserves consistency.
Transaction based services
Transaction processing was developed for database management applications but is also applicable to distributed file systems or any other distributed data applications. A transaction service is a form of file or database service that provides a construct to allow a client to group together the desired service operations that comprise the transaction.
It offers an interface for opening a transaction, which causes the generation of a new transaction identifier supplied to the client for associating subsequent operations. The identifier may also be used in determining an order among transactions. A number of operations are then specified by the client as part of the transaction and the service attempts to perform the complete transaction, preserving the ACID properties. The close transaction request from the client will deliver either a commit or abort result from the server.
During the transaction, a client can make a series of updates to a record or file which are later referenced by other operations within the same transaction. To allow for this, before any updates are committed the server will provide a workspace, or copy of data modified, which is only visible to that transaction.
Implementing Transactions
The implementation of a transaction service must handle concurrent transactions and be capable of recovering from failure.
Concurrency
Concurrent transactions must have serial equivalence. The approaches to handling concurrent transactions can prevent inconsistency, avoid inconsistency or validate consistency before committing. Forcing all transactions to occur serially prevents inconsistency but may be unnecessarily restrictive and can produce long delays for the completion of transaction operations. This argument favours alternative approaches.
We now look at three methods for controlling the concurrent execution of transactions:-
Locking (Preventing Inconsistency)
Each item is locked by a transaction that accesses it so that no other transaction may access the item until the transaction in possession of the lock commits or aborts.
Optimistic Concurrency Control (Validate Consistency)
It is hoped no conflicts of data will occur. Transactions proceed until they are ready to commit, when there is a check. If conflicts with earlier transactions have occurred, a transaction is aborted and must be restarted.
Timestamps (Avoid Inconsistency)
Each transaction has a timestamp and data items are timestamped each time they are accessed. Transactions are aborted and restarted when they are too late to perform an operation on a particular item.
Locks and Simple Locking Rules
1. When a client operation accesses an item within a transaction:
(a) If the item is not already locked, the server locks it and proceeds to access the data for the client.
(b) If the item is already locked for another transaction, the client must wait until it is unlocked.
(c) If the server has already locked the item in the same transaction, it can proceed to access the item.
2. When a transaction is committed or aborted, the server unlocks all items it locked for the transaction.

Note that the use of locks can lead to deadlock, when for example, a pair of clients each have locked an item which the other requires to complete its transaction.
A lock can be defined as a record composed of three variables:-
A two-state variable that indicates whether it is locked or not.
A condition variable on which processes may wait or signal.
A variable containing the identifier of the transaction that set the lock.
A condition variable is similar to a semaphore, where a waiting process is blocked and the signalling procedure releases each process in turn, fairly.
Locks can be applied at different levels of granularity. For example, in a file service we could lock entire files or with finer granularity, just the records required by the client transaction. For general use, locking at the level of logical records is preferred. This may involve a considerable amount of storage for allocating and managing locks and is most likely to be stored separately from the data itself.
Two-Phase Locking
The first phase of each transaction is a 'growing phase' during which new locks are acquired. In the second phase of a transaction, locks are released (a shrinking phase). This is called two-phase locking.
During the first phase, a transaction has its own tentative record of changes which is invisible to other transactions. Until a transaction commits or aborts it cannot be decided whether other transactions should use the values of affected items as they were before the transaction started or as they will be after the transaction has committed.
An extreme implementation of two-phase locking releases all locks only after a transaction has committed and the data items have been permanently updated. This simplifies the implementation of serializable transactions but does not deal adequately with sharing and concurrency. Concurrency can be increased by releasing locks as soon as possible. There are several difficulties with this approach however.
Suppose the transaction t1 updates data item a, and then releases the lock on a. Suppose the next transaction t2 reads the value a. If transaction t1 aborts, t2 must abort also because t2 has read dirty data. The abort of t2 may cause other rolling or cascading aborts. Since t2 can commit only if t1 can commit, t2 has a commit dependence on t1. The commit dependencies must be tracked and the commit of t2 must be delayed until after the commit of t1.
Read and Write Locks
Some transactions read items but do not alter them and this does not conflict with other transactions that only read the same items. A single lock used for both read and write operations constrains concurrency more than necessary.
A write lock is used on any item affected by a TWrite operation and a read lock is set on any other items accessed by TRead operations. An item locked with a write lock cannot be shared by another transaction. An item locked with a read lock cannot have its value changed by another transaction but may share its read lock with other transactions.
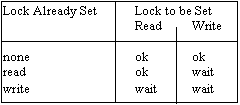
The table above is an extension to the simple locking rule (b) given earlier. In addition the rules would include:-
1 (d) If a transaction is attempting to write an item on which it has previously placed a read lock, the read lock is converted to a write lock.
Lock Timeouts
As a means of resolving possible deadlocks, a timeout can be associated with each lock. When the lock is acquired it is considered invulnerable for a limited period of time. After this time, if there are contending processes for the lock, the lock is broken and the transaction holding it is aborted. The lock is then reassigned. If there are no contending processes however, the lock remains in place but is vulnerable, as described, should any process request it.
Timeouts have two main problems. In an overloaded system where transactions may take longer, timeouts will occur more frequently and increase the number of aborted transactions and recovery activity. It is also difficult to decide on the length of a timeout suitable for all transactions. If a deadlock detection approach is used instead, the transaction server can look at the wait-for graph and decide which locks to break.
Intention-to-Write Locks
Separate read and write locks are preferable to simple locks. However, a read lock prevents any transaction from writing the locked item. A better method, allowing more concurrency, might be to allow a transaction that writes to proceed with its tentative writes until it is ready to commit. The value of the item will not change until the writing transaction commits and so if it is suspended at that point, the item cannot change until the read lock is released.
One scheme is to use an intention-to-write lock (I-write) and a commit lock together instead of a write lock. As each TWrite occurs, an I-write lock is used to lock an item. Read locks are compatible with I-write locks until the transaction is ready to commit. This means concurrent reads can take place despite the existence of an I-write lock and an I-write lock can be acquired even if read locks exist on an item. When the transaction is ready to commit, the I-write lock must be converted to a mutually exclusive commit lock (incompatible with all other locks) as soon as all read locks on the item are released.
If there are timeouts on locks, the rules for converting I-write to a commit are:-
If another transaction has a vulnerable read lock, the server breaks the vulnerable read lock and converts the I-write lock to a commit lock.
If the I-write lock is vulnerable and another transaction has a read lock that is not vulnerable, the server aborts the transaction holding the I-write lock.
If neither the I-write lock nor the read lock of two transactions are vulnerable, the server waits until one of these is the case or the read transaction may complete and release its lock.

Disadvantages of Locks
Locking is necessary only in the worst case where data being read by some transaction(s) is being written by another. This may be unlikely most of the time but lock usage always requires the precaution and so incurs considerable overhead even when no danger exists.
Locks can cause deadlock. Deadlock prevention reduces concurrency. Deadlock resolution with timeouts or detection methods is not satisfactory for interactive applications as aborted transactions must be restarted and so take longer to complete.
Locks are only released at the end of a transaction, to allow a transaction to be aborted, and so reduce the potential for concurrency.
Timestamp Ordering
Two phase locking orders transaction operations by the time a shared item is first locked. We have seen already the application of logical clocks and timestamps for ordering events. Conflicting operations in interleaved transactions can be ordered using these techniques as well.
Each operation in a transaction is validated when it is carried out and if the operation cannot be validated the transaction is aborted and subsequently can be restarted.
Each transaction is assigned a timestamp.
A transaction's request to write a data item is valid only if that data item was last read or written by older transactions.
A transaction's request to read a data item is valid only if that data item was last written by an older transaction.
Tentative values of each data item are committed in the order determined by the timestamp of the transactions. This is achieved by transactions waiting where necessary for earlier transactions to complete their writes. Write operations may be performed by the server after the close transaction has returned, without making the client wait. But the client must wait when read ops need to wait for earlier transactions to finish. This cannot lead to deadlock since transactions only wait for earlier ones and so no cycle of dependency can exist.
We have already discussed a number of schemes for generating timestamps and also how a total ordering of identifiers can be agreed among distributed servers. The following implementation of timestamp-based concurrency control ignores these issues.
Implementing Timestamp-based Concurrency Control
Every data item has a read timestamp and a write timestamp. The server updates these, whenever read or write operations affecting the item are performed, using the timestamp of the transaction. When a transaction is in progress there will be a number of data items with tentative new values and timestamps. When committed these become permanent.
The server checks read and write operations for serializability with other transactions by inspecting the timestamps of the relevant items including tentative items belonging to incomplete transactions.
If the timestamp on a data item is the same as that of the requesting transaction, it must have been set by the current transaction and may proceed. The possible conflicts between two transactions are shown below:

When the timestamps differ the following rules can be used in an example implementation:-
For Write Operations
w1: The timestamp of the current transaction is more recent than the read and (committed) write timestamps of the data item. A tentative write operation may proceed.
w2: The timestamp of the transaction requesting the write is older than the timestamp of the last read or committed write of the data item. This means the write is arriving too late and the current transaction is aborted.
The tentative values of an item can be kept in a list ordered by their transaction timestamps. The effect of a tentative write is to insert the tentative value in the appropriate place in the list. In the case of a read operation only the write timestamp need be considered.
For Read Operations
r1: The timestamp of the current transaction is more recent than the write timestamps of all committed and tentative values. The read can be done immediately if there are no tentative values otherwise it must wait for those transactions to complete.
r2: The timestamp of the current transaction is older than the timestamp of the most recent (committed) write to the data item. The read is too late and the transaction is aborted.
r3: The timestamp of the transaction is older than that of a tentative value of the data item made by another transaction, although more recent than the permanent data item. The transaction is aborted.
When a client closes a transaction, the server has to make tentative values resulting from write operations permanent. A transaction can only reach this point if its operations have been consistent with earlier transactions. Therefore it can always be committed although it may have to wait for earlier transactions that have tentative copies to commit.
Consider the following example. T is a transaction which reads a and b and then writes both. U is a transaction that reads and writes c and then reads and writes b. tT and tU (tT<tU) are the timestamps of the transaction T and U and are both greater than the initial timestamps of items a,b and c.

In this example, the outcome is the same as for read and write locks with timeouts to avoid deadlock.
A slight improvement to the timestamp scheme described could reduce the number of transaction restarts with the following improvement:
If a write is too late, then if it had arrived in time its effects would have been overwritten anyway. The write can therefore be ignored instead of aborting the transaction provided that the transaction which modified the item did not read it first.
Note that this doesn't apply in the example above as U has read item b and allowing the write in transaction T would violate serializability.
Timestamping is similar to locking in that the server detects conflicts as each item is accessed but the additional information in the timestamps allows some transactions to proceed which would otherwise be prevented with locks. Immediate abortion in timestamping requires transactions to be restarted whereas with locking, transactions wait on locks. The wait that occurs with the timestamp method when a read operation encounters a more recent tentative value is equivalent to waiting on a write lock.
Optimistic Concurrency Control
Two phase locking is a pessimistic approach which may needlessly block transactions. Timestamp ordering allows some transactions to proceed freely but at the expense of more aborts after carrying processing of some operations. This idea can be extended to allow the entire processing of the transaction to complete, using tentative copies of shared items, and then validate the transaction before making the affect permanent.
Optimistic concurrency control is based on the observation that, in most applications, the likelihood of two client transactions accessing the same data item is low. Transactions are allowed to proceed as though there were no possibility of conflict until the client issues a CloseTransaction request.
During the first phase, read requests are performed immediately and write requests are recorded in tentative form. A read set and write set of items is associated with each transaction. After the CloseTransaction request, the transaction enters the second phase where it is validated to establish whether write operations, the third phase, should be made permanent or whether the transaction should abort.
The validation phase of transaction T checks if a transaction exists that has a write phase which occurred after the beginning of the read phase of T, but before the validation phase of T and has a write set which intersects the read set of T. If so, T may have accessed inconsistent data and so is not serializable with the other transaction and must be restarted.
Each transaction is assigned a unique monotonically increasing sequence number when it completes the validation phase (i.e. commits). The number of a transaction defines its position in time.
Let Ts be the highest sequence number at the start of T and Tf be the highest sequence number at the beginning of its validation phase. All transactions between 'time' Ts +1 and Tf have been allowed to commit after T began reading and could have caused inconsistent access to data by T. The following algorithm checks this:
valid := TRUE;
for t := Ts + 1 to Tf do
if writeset[t] Ç readset[T] ¹ f then
valid := FALSE;
if valid then {
/* Enter Write Phase */
increment counter;
assign T value of counter ;
}
To prevent problems caused by overlapping of validation tests in concurrent transactions, the validation and write phases are implemented together as a critical section so that only one client transaction at a time can be in the process of committing.
A read only transaction doesn't have a write phase, but still has to be validated. The optimistic approach is suitable only in environments where conflicts are unlikely to occur, such as query dominant systems, in order to avoid transaction restarts.
![]()
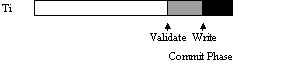
![]()
![]()
![]()
![]()
![]()
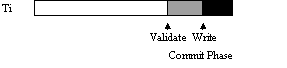
Three ways transactions may overlap in time with
optimistic concurrency control
![]()
![]()

![]()
![]()
![]()
![]()
![]()
![]()
Concurrent Transactions on Replicated Data
Up to now we have identified a number of approaches for dealing with concurrent client transactions at a single server. Of these techniques, locking is the most common and general purpose approach partially due to its inherent fairness. There are a number of ways of implementing locking among a group of servers maintaining replicated data.
Completely Centralised Approach
Update transactions to replicated data are handled by a central site. Each server manages replicated data and forwards update transactions to the central site which can carry them out either sequentially or in some other way that guarantees serializability. The central site serializes the operations using sequenced multicast messages to the replicated data servers. Although this scheme is very simple, it offers poor reliability if the central site crashes and can be a bottleneck.
Centralised Locking
To eliminate bottlenecks, a scheme which allows distributed transaction processing but with centralised lock management is as follows. Before a server executes an update transaction, it requests all locks from a central site via a lock request message for the data items it accesses. If all locks can be granted, the central site responds with a lock grant message and a sequence number. Otherwise the request is queued until all locks can be granted. There is a queue for each data item and a request waits in only one queue at a time. To prevent deadlock, transactions request locks in a predefined order.
Each server can execute the transaction using its own local data and then broadcasts an update to all other sites which are applied in order of sequence number. When the central site receives the update message, it releases all locks set by the corresponding transaction.
Primary-Site Locking
In this method lock management is distributed among all sites. Each data item, irrespective of the number of copies, has a single site designated as its primary site. All updates for an item are first directed to its primary site. A transaction consists of a series of actions that might take place at different sites. For a query, a series of requests are either directed to a local copy of an item (with some possible loss in consistency), or to the primary copy. For an update, the data access requests must be directed to the primary site. This activity is coordinated by a process at the server where the transaction originated known as the master.
Distributed Two-Phase Locking
Two phase locking can be applied to concurrency control in transaction-based replicated data services by locking, in exclusive mode, all copies of data to be modified and by locking, in shared mode, any one item of data to be read.
Locking data items in the write set of a transaction requires a large number of messages, causing an additional delay for each write lock (on top of the contention delay) since a reply must arrive from each server agreeing that the item is locked before use. The implementation of a read lock is more efficient as it need only be placed on an item at one site. This prevents a write lock ever being acquired by another transaction.
Site failure is a problem. If a transaction has a read lock on a data item d at site Sj and site Sj crashes, another transaction can put a write lock on d since all the available sites do not have a read lock. Consequently, one transaction has a write lock and another has a read lock for the same item, leading to inconsistency.
One approach to solve this is that when a transaction reaches a point at which all its locks have been acquired, it checks to make sure that all the data item it read are still available and locked. If a site at which it holds a read lock has gone down, then the data item is considered unavailable and the transaction aborts.
Nested Transactions
A nested transaction is a subtransaction contained within another transaction. Subtransactions can run concurrently but are serialisable with respect to the parent transaction. Subtransactions can also fail, but this does not force the parent to fail as they can be restarted. Subtransactions can therefore provide a limited kind of firewall against failures. Subtransactions can be used to implement zero-or-once semantics for RPC operations where the caller can be aware of whether each call was done or not.
Implementing nested transactions requires some extensions to the two-phase locking technique. A transaction is allowed to acquire a lock only if all conflicting locks are currently held by ancestors. In other words, no other concurrent transaction holds a conflicting lock at any level of the transaction tree. When a subtransaction commits its locks are inherited by the parent. When it aborts its locks are discarded.
The effects of a subtransaction are not permanent until the top-level ancestor of the subtransaction commits. This means that a full two-phase commit protocol where all sites must agree to commit the transaction is not needed when a subtransaction commits. A local commit decision can be made which can be verified later during the commit for the top level transaction.
Transaction Recovery
A transaction processing system typically has the following structure:-
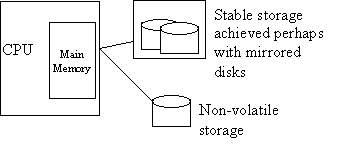
Consider the following categories of failure:-
Transaction Abort: This may be due to a client request or to eliminate a deadlock or possibly a transient hardware fault. If the transaction has performed any operations, they must be undone.
System Crash: Main memory and active processes are lost but non-volatile storage and stable storage survive.
Media Failure: Some of the non-volatile storage is lost.
Catastrophe: An irrecoverable event where stable and non-volatile storage is
lost.
Transaction Aborts
There are four kinds of action that might be performed by a transaction.
Updates: Read and modify the server state.
Read: Read the server state only.
Commit: Apply transaction operations.
Abort: Do not apply any transaction operations.
There are two basic methods that can be used for recovering from transaction aborts, both employ logs which would be written to stable storage. Stable storage is constructed from redundant forms of non-volatile storage which duplicate block information. It is designed to ensure that any essential permanent data will be recoverable after any single system failure. If the failed component can be replaced or repaired quickly, very high mean-time to failure can be achieved.
Update-in-place: Apply the updates as the transaction runs, but undo them if it aborts. The implementation for the different types of transaction actions would be as follows:
Update: Record an undo record in an undo log and update the server state. The
undo record could contain the old value of the updated record.
Read: Read the desired item from the server.
Commit: Discard the transaction's undo log.
Abort: Use the undo records in the transaction's undo log to reverse the effect
of the operations and apply them in reverse order to the original
transaction sequence.
Deferred-update: Record a transactions updates while it runs and apply these when it commits. The implementation for the different types of transaction actions would be as follows:
Update: Record a redo record in a redo log (Intentions List) The redo record
could contain the new value of the updated record.
Read: Combine the redo log and the server state to determine the appropriate
data value. This is necessary because an earlier update by the same
transaction might have modified the data item.
Commit: Update the database by applying the redo log in order.
Abort: Discard the transactions redo log.
Comparing the two schemes, it can be seen that read and commit operations are cheaper when the update-in-place scheme is used, however abort is cheaper under the deferred-update scheme.
It makes sense to optimise the performance of reads as these occur more frequently. It also makes sense to optimise the performance of commits as we would hope that these would occur more frequently than aborts. Both of these reasons would suggest using the update-in-place scheme.
Both methods place different constraints on concurrency. Update-in-place requires locks to be held until the transaction commits or aborts whereas deferred-update allows the use of I-Write and Commit locks allowing greater concurrency.
Crash Recovery
Typically a transaction processing system will store its data on non-volatile storage with some of it cached in main memory and uses other non-volatile storage for storing recovery information needed to repair the data after a machine crash. Normally the recovery information and the data would be on separate disks to avoid contention.
Two problems need to be solved:
A disk supports atomic actions (read or write) at the block level. A transaction may update a number of different blocks, which must be done atomically.
We must make efficient use of available storage. We can reduce the latency of writing to non-volatile storage by storing the writes in main memory and performing them asynchronously. This allows the application to continue without having to wait for the writes to be flushed and it also allows several updates to one block to be accumulated before performing the write. The blocks to be written may be organised sequentially to improve disk performance.
A solution:
Recovery data is stored in a sequential log stored on disk. Log records are written asynchronously and are buffered in main memory. Log records include update records and undo/redo information and the commit/abort status of transactions.
Transaction aborts are handled using an update-in-place strategy. Records are also written to the log as each operation is undone during an abort, to record the changes to the state of the data.
After a crash, any transaction that does not have a commit record in the log on disk is aborted. When a transaction commits, we need to make sure that its commit record is in the log on disk and this can be done by forcing(flushing) the buffered log to disk when we append a commit record. The transaction system should not acknowledge the commit to the client until it has been stored in the log on disk. The requirement to flush the log for commits is called the redo rule.
The log is used to repair the data on disk (part of which was in memory) after a crash. Some blocks may have uncommitted data and others may be missing committed updates. The undo records in the log for active or aborted transactions are used to undo the uncommitted updates. The redo records for the committed transactions are used to install the missing committed updates.
Some synchronisation is required between writing cached disk blocks to disk and writing buffered log records to disk. Otherwise we could have uncommitted data on disk without the appropriate undo records in the log. To ensure that uncommitted updates can be undone, the write-ahead log rule or undo rule says that before an update to a disk block is written that an undo record for that update must be recorded in the log on disk. The redo and undo rules allow us to recover after a crash.
The crash recovery process is then as follows: First redo all updates in the log including updates for 'undo'ing aborted transactions. Then undo all transactions that have no commit or abort record.
The redo rule ensures the durability of transactions. The undo rule constrains the operation of the cache manager slightly, by delaying writes until log records are on disk.
Recovery from Media Failure
This category involves failure of non-volatile storage which may occur, for example, due to corruption during a crash (e.g. power failure), due to random decay or wear and tear over time, or by a permanent failure such as a head crash.
To recover from this type of failure, we must have another copy of the data or sufficient information to allow us to make another copy of the data. This data and recovery information must be stored on stable storage implemented as mirrored disks or by storing copies at different locations on a network. There is a cost factor associated with maintaining stable storage which must be weighed against the effects and probability of a catastrophe occurring. Firstly, there is a hardware cost as more storage space is required for storing multiple copies of data. Then there is a runtime cost for performing the additional write operations either to a mirrored disk or to more distant copies on the network and maintaining consistency.
The data stored on stable storage consists of an archive copy (or last recorded checkpoint) together with an archive log. The archive log contains redo information for committed transactions only. If a disk copy fails, it can be recovered by installing the archive copy and reapplying the updates in the log. If only part of the disk fails, it is not necessary to rebuild the entire data set, but only the failed set from a subset of the archive and log. Getting a consistent checkpoint may involve stopping all transactions while the archive is recorded on stable storage, thus limiting concurrency. The frequency of this operation would affect runtime costs.
Distributed Recovery
All sites involved in a transaction must reach a consistent state. That is, all must commit or all must abort a transaction. The transaction should only be committed if all sites are able to satisfy the redo rule.
The most common solution to solving this problem is the two-phase commit protocol. In this protocol, one of the sites is the coordinator and the rest are participants. An example of a two-phase commit protocol is given below:-
Executed by Coordinator
Phase 1
send vote request to all participants
wait for receipt of vote from all participants
Phase 2
if all votes are yes then
force commit to log on disk
broadcast commit to all participants
else
broadcast abort to all participants
On timeout broadcast abort to all participants
On receipt of all acknowledgements from participants, the log entry may be deleted.
Executed by Participants
Phase 1
wait for receipt of vote request from coordinator
record status of vote in log and send vote to coordinator
if vote = no then
abort transaction
else
Phase 2
wait for delivery of decision message
if decision is abort then
abort transaction and write record to log
else
commit transaction and write record to log
send acknowledgment of decision to coordinator