Processes and Threads
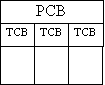
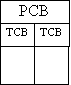
A process is a program in execution. Traditionally a process consists of an address space with a single thread of control operating within that address space. The operating system maintains environmental and accounting information for each process under its control in a process control block(PCB). This includes the processor state, descriptors for open files and communication links, I/O buffers, locks and other OS resources in use by the process as well as keeping track of past resource usage for cost and auditing purposes. The PCB contains the necessary information for context switching by the native operating system.
A process is sequential if a single thread of control regulates its address space.
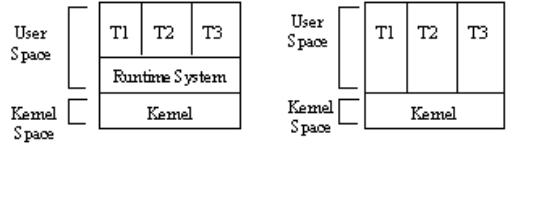
Allowing multiple threads of control in a process introduces concurrency. Each thread shares and operates within the common process address space but each has its own local processor state maintained in a thread control block(TCB) associated with the process. Thread management is very lightweight as thread creation and context switching involves little overhead. Threads communicate and synchronize with each other using fast shared memory mechanisms.
Single thread process Multiple thread processes OS Kernel and
Thread Support
![]()
![]()
![]()
Threads are quite useful for distributed system applications. Many systems interact using a client/server model of communication where a server process listens for client requests, executes them and returns the results. If the server was operating as a sequential process and attempting to support multiple client requests then two or more concurrent requests would have to be executed serially by the server process. This would keep a number of buffered unanswered requests waiting indefinitely until the server finished with earlier ones. The outstanding requests may timeout giving the client the impression that the server has failed.
One alternative is to have the server fork a new process to deal with every new request. A listener process receives messages and creates a new process to execute the service passing it the parameters from the client. Requests then execute asynchronously under the control of the operating system. The listener process could also provide an immediate initial response to the client if required. The problem however is that process creation can be quite slow as the operating system has to find sufficient free memory space for the process and set up other parts of its control block. The operating system also has a limited number of PCBs available. This would be very inefficient if the amount of time spent servicing requests was small. In addition, if the server is maintaining data of some kind, then the server processes must synchronize their accesses to this data using interprocess communication introducing propagation delays which reduce server performance.
A better alternative is to have the server create threads to deal with new requests. A controlling thread receives new requests and creates a lightweight thread to execute it. This is a more scaleable approach from the operating system's point of view as it is a more efficient use of system resources. Coordination and synchronization between the cooperating parts of the server process are achieved more efficiently with shared memory mechanisms.
Threads allow parallelism to be combined with the easily understood blocking communication of the client/server model. That is, programmers feel more comfortable with sequential code execution and blocking communication because it is easier to specify. We can retain the model of our sequential process interaction with blocking calls but still achieve parallelism in the application with threads. This is because when a thread in a process blocks, waiting for a reply from a server, another thread within that process can be scheduled and so the process does not lose its allotted CPU time. Another benefit is that threads allow the process to take advantage of a multiprocessor system.
There are a number of ways of organising this parallelism within a process depending on its application. The first two are alternatives for server process organisation. The third would be more suited to producer consumer structured applications.
Listner/Dispatcher Team of Equal Priority
Threads Threads with specific
tasks
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()
![]()



Slave
Threads
Kernel Kernel![]()
![]()
Incoming Request Incoming Request Incoming Request
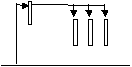
The first organisation uses one thread to listen for client requests and then chooses a free slave to carry out the request (or it can create one) while it goes back to listen for more client requests. Thread creation can be dynamic, that is the thread count can reflect demand for the service. Only one thread has access to the incoming messages.
The second organisation views the threads with equal priority operating as a team to carry out the requests for service. Each has access to the incoming requests. As threads operate autonomously, apart from the use of shared memory mechanisms for coordinating access to the process data, the number of threads is statically defined when the process is initiated.
The third organisation demonstrates a thread pipeline where the output of one thread is used as the input to the next. Requests are delivered to the first thread in the pipeline. Some applications have organisations similar to this e.g compilers. Unix commands can be composed of a number of commands each of which pipes its output to the next. For example, "ls -l | grep dkelly" to find all files owned by or with the name of dkelly in the current directory. The unix shell creates separate processes for each part of the command and connects the standard output of one to the standard input of the next using the pipe communication mechanism. If "ls -l" and "grep dkelly" could be executed by separate threads the command could be modeled as a single process as above.
Threads are now supported by all modern operating systems to allow programmers write concurrent programs easily and efficiently. For example, many windowing applications use threads because event coordination between the different windows is easier as the threads are sharing memory.
Consider an application program such as a Word Processor. The application runs as a process in the system with the code of the word processor and its data both stored in the process memory space. If the application is multithreaded then one thread can be reading keystrokes while another thread is spell checking while another thread is checking grammar while another is repaginating or drawing graphics and all are sharing access to the same program code and data.
Consider an internet server program such as a web server or a database. If the server is multithreaded, then it could create a new thread to handle each new request enabling it to handle more than one request at a time. If a single threaded server was used, then each request would be queued and serviced in turn and, if the server was busy, the client software may have to wait a long time for a response. This unresponsiveness can sometimes lead to timeout problems. A new thread for each concurrent request means that the server can acknowledge the request right away while continuing to process requests from other clients.
Another option is to have a finite number of threads created when the server starts up. A client request can be serviced by any available thread but must wait until a thread becomes available to handle it. This method avoids thread creation time for each request and limits the resources used by the server if resources are scarce or the machine is not able to handle a high degree of multithreading.
Multithreaded applications can utilise more operating system resources simultaneously within the one application. In a multiprocessor system, the application may run quicker if multiple threads can execute simultaneously. Or one thread could be waiting for an I/O device while another thread is using the processor. In contrast, single threaded processes would block entirely when waiting for I/O.
For simplicity and understandability, programmers of client/server applications prefer to use blocking communication primitives. This means the client is blocked waiting for the server’s response. This does not facilitate concurrent execution of the client and server code without multithreading. With multithreading, a client or server thread can wait for communication while other threads within the application execute other functions.
Implementing Threads
User Space Implementations
The API for creating and managing threads can be implemented as a user space library linked with the program. This technique does not require any operating system support for threads. Invoking a function in the library to schedule a thread or create or destroy a thread results in a local function call in user space and not a context switch required by a system call. A context switch to the kernel would block all threads in the process, as the kernel is unaware of the existence of the threads. The library could intercept any system call that had the potential to block the process and decide to schedule another thread of its choice instead. It can save the TCB of the calling thread somewhere in the process memory space and load the TCB of another thread, all without a true CPU context switch. At some stage kernel calls must be executed, in which case the issuing thread effectively blocks the entire process.
The context switching of threads by the runtime system requires very little overhead and the application programmer has control over the scheduling policy for threads within the process. This scheduling is non-preemptive however, as a thread has to call a runtime procedure before a context switch can occur.
For older operating systems that were designed to support only the single-threaded process model, user space implementation is the only option apart from having to redesign the operating system. Redesigning the operating system could mean many of the existing applications would no longer run.
Kernel Space Implementations
If thread management is implemented by the kernel then the kernel will maintain code and data structures for the thread management API. All calls that might block a thread are implemented as system calls and cause a context switch first to the kernel.
The kernel decides whether to schedule another thread from the same process or from a different process. It is clear that context switching between threads of the same process will take longer than if implemented in user space.
Implementing threads in kernel space offers greater flexibility and efficiency.
A thread issuing a system call does not necessarily block all other threads in that process.
Threads can be scheduled onto separate CPUs on a multiprocessor system offering true application concurrency.
Threads compete on an equal basis for CPU cycles and they may be preempted by hardware easily.
The kernel itself could be implemented as a multithreaded process providing services to user processes by the execution of kernel threads. In this way the kernel does not block all processes while executing a system call. This requires careful design of the kernel data structures to allow for multithreaded activity and is necessary especially if the underlying hardware has a multiprocessor architecture.
Note that thread implementation and scheduling is limited to single computer system environments. Parallel programming technologies such as MPI and PVM are used for managing parallel computations in distributed environments.
Multithreading Models
In the last section we distinguished between threads implemented at the user level and threads at the kernel level. There are three common ways of mapping these entities.
Many to One Model
The many to one model maps many user-level threads to one kernel thread. Thread management is done efficiently by a user space thread library, but the entire process will block if a thread makes a system call, it cannot use multiprocessors or implement preemptive scheduling. Green threads (Solaris) and GNU Portable threads use this model.
One to One Model
The one to one model maps each user thread to a kernel thread allowing other threads to run when one makes a blocking call, and allows use of multiprocessors. Drawback is that creating the kernel threads can burden the performance of the application. Most implementations restrict the number of threads that can be created. Linux, Solaris 9 and Windows operating systems use this model.
Many to Many Model
The many to many model multiplexes many user level threads to a smaller or equal number of kernel threads. In this way, although the number of kernel threads may be restricted, the developer can create as many user-level threads as required. Obviously, if there are fewer kernel threads then this will restrict concurrency but the model allows use of multiprocessors and allows the kernel to schedule other threads when a thread performs a blocking system call. A variation to this model allows some user-level threads to be bound to a kernel thread. This variation is supported by IRIX, HP-UX, and TRU64 Unix.
Process & Thread Management in The Unix Operating
System
Ref: Operating System Concepts with Java Chapter 4.3
Recall Process Creation and Termination
In Unix, every process is identified by a unique process identifier. A new process is created by the fork() system call. The original process is known as the parent and the new process is known as the child. The fork() system call creates an exact duplicate of the parent process environment including its memory space, code, data and stack and pointers to open I/O devices. This allows the child to easily share any communication channels or other resources with the parent. Both processes continue execution in their own address spaces at the program instruction immediately following fork() with one difference. The return code from the fork() is zero in the child process’s environment whereas the return code for the parent is the new process ID assigned by the system to the child.
Typically, the exec() system call is used after a fork() system call by one of the processes to replace that process’s memory with a new program. The exec() system call loads a binary file into a process’s memory (destroying the existing program image) and starts execution.
The C program below demonstrates the use of fork() and exec() system calls.
#include
<stdio.h>
#include
<unistd.h>
int main(int argc,
char *argv[])
{
int pid;
pid = fork();
if (pid < 0) {
fprintf(stderr, “Fork failed”);
exit(-1);
}
else if (pid == 0) { /* child process */
execlp(“/bin/ls”, ”ls”, NULL);
}
else {
/* Parent process */
/* Wait suspends
execution of current process until a child has ended. */
wait(NULL);
printf(“Child complete”);
exit(0);
}
}
When a process terminates by executing an exit() system call the operating system deallocates and reclaims all the resources used by the process. Termination can also occur due to program run time errors or due to signals sent from another process (usually the parent) aborting the child.
Some systems, like VMS, do not allow a child process to exist if its parent has terminated. Killing the parent results in cascaded termination of the child processes.
Ref Operating System Concepts with Java - Chapter 5.3
In a multithreaded program the semantics of fork() and exec() change. Some Unix systems implement two versions of fork() – one that duplicates all threads and another that duplicates only the thread that invoked the fork(). The latter version can be used if the new process calls exec() immediately. The exec() system call replaces the existing process including all its threads with the program specified in the parameter to exec() so there is no point in duplicating these threads with the fork() statement.
Thread Programming Interfaces
The API used for manipulating threads in Unix is the POSIX pthread library. The Portable Operating System Interface project (POSIX) developed by the IEEE Computer Society, the Open Group and the International Standards Organisation has resulted in globally agreed standards for specification of Unix system interfaces to allow for portable applications and boundaryless information flow. This work has been taken over by the IEEE Portable Applications Standards Committee (PASC).
The specification may be implemented differently from one Unix system to the next, but the API will be constant. The pthread library may be implemented as a user space library or as a kernel level library. Kernel level thread support is not fully implemented yet in Linux although it is in Sun’s Solaris making Solaris potentially more attractive as a platform for high performance enterprise computing with high parallelism requirements.
The Win32 thread library is a kernel level library used by Microsoft operating systems such as Windows 95/98/NT, Windows 2000 and Windows XP.
The Java thread API can be implemented by pthreads or by Win32.
pthread Thread Creation and Termination
A new thread is created by the pthread_create() function. The function takes four parameters:-
The first is an identifier, associated with the thread structure, of type pthread_t which is passed by the program to the pthread_create() function.
The second parameter specifies attributes the new thread will have such as stack size and scheduling attributes. A null parameter means that default values will be used.
The third parameter specifies where the new thread will begin execution in the program. This will identify a function to be executed. The thread will terminate when it comes to the end of the function.
The fourth parameter is a pointer to a list of arguments to be passed to the function the thread will execute.
A thread exists until it both terminates and has been detached.
Thread Termination
A thread can terminate when it comes to the end of its function. The return value of the function is saved and returned to the caller of a pthread_join() function. The thread can also terminate if it calls pthread_exit() anywhere in its code. The return value must point to a static data structure which exists after the thread has terminated and not to local variable data on the threads local stack.
But in all cases the data structure representing the thread remains in the system until it has been detached.
Detaching a Thread
A thread can be detached either by another thread calling pthread_detach() or by another thread calling pthread_join() which allows a return value to be passed back. The pthread_join() function blocks the caller until the thread terminates.
Note: All pthread functions return 0 if successful, otherwise an error code.
Example of pthread creation and termination
#include
<stdio.h>
#include
<stdlib.h>
#include
<pthread.h>
void
*print_message_function( void *ptr );
main()
{
pthread_t thread1, thread2;
char *message1 = "Thread 1";
char *message2 = "Thread 2";
int
iret1, iret2;
/* Create independent threads each of
which will execute function */
iret1 = pthread_create( &thread1,
NULL, print_message_function, (void*) message1);
iret2 = pthread_create( &thread2,
NULL, print_message_function, (void*) message2);
/* Wait till threads are complete before
main continues. Unless we */
/* wait we run the risk of executing an
exit which will terminate */
/* the process and all threads before the
threads have completed. */
pthread_join( thread1, NULL);
pthread_join( thread2, NULL);
printf("Thread 1 returns:
%d\n",iret1);
printf("Thread 2 returns:
%d\n",iret2);
exit(0);
}
void *print_message_function(
void *ptr )
{
char *message;
message = (char *) ptr;
printf("%s \n", message);
}
Compile:
cc -lpthread pthread1.c
Run: ./a.out
Results:
Thread 1
Thread 2
Thread 1 returns: 0
Thread 2 returns: 0
Java Threads
ref: Operating System Concepts with Java (6th
Edition)
Java is one of the small number of languages that provide support at the language level for the creation and management of threads. Threads are managed by the Java Virtual Machine, not by a user-level or kernel-level library.
All Java programs comprise at least one thread of control.
One way to create a thread explicitly is to create a new class that is derived from the Thread class and to override the run() method of the Thread class.
class Worker1
extends Thread
{
public void run() {
System.out.println(“I am a worker
thread”);
}
}
public class First
{
public static void main(String args[]) {
Thread runner = new Worker1();
runner.start();
System.out.println(“I am the main
thread”);
}
}
Calling the start method of the Thread class for the new object allocates memory and initialises a new thread in the JVM and then calls the run method.
Another option to create a separate thread is to define a class that implements the Runnable interface. As Java does not support multiple inheritance, a subclass would not be able to extend the Thread class so it can implement the Runnable interface instead. The Runnable interface is defined as follows:-
public interface
Runnable
{
public abstract void run();
}
When a class implements Runnable, it must define a run() method. The Thread class also implements the Runnable interface.
class Worker2
implements Runnable
{
public void run() {
System.out.println(“I am a worker
thread”);
}
}
The code below shows how threads can be created using the runnable interface.
public class Second
{
public static void main (String args[]) {
Thread thrd = new Thread(new Worker2());
thrd.start();
System.out.println(“I am the main
thread”);
}
}
Windows XP Threads
Windows XP implements the Win32 API which is the primary API for Microsoft Operating Systems. A windows XP application runs as a separate process with each process containing one or more threads. Windows XP uses one to one mapping but also provides support for the many to many model.
The components or context of a thread include:-
A unique thread ID
Pointer to the process to which the thread belongs
The address of the routine where the thread starts
A register set representing the processor status
A user stack when running in user mode and a kernel stack when running in kernel mode.
A private storage area used by various run-time libraries and dynamic link libraries.