Process Load
Distribution
Distributed
scheduling is concerned with distributing the load of a system among the
available resources in a manner that improves overall system performance and
maximises resource utilisation.
The
basic idea is to transfer tasks from heavily loaded machines to idle or lightly
loaded ones.
Load
distributing algorithms can be classified as static, dynamic or adaptive. Static means decisions on
assignment of processes to processors are hardwired into the algorithm, using a
priori knowledge, perhaps gained from analysis of a graph model of the
application. Dynamic algorithms gather system state information to make
scheduling decisions and so can exploit under-utilised resources of the system
at run time but at the expense of having to gather system information. An
adaptive algorithm changes the parameters of its algorithm to adapt to system
loading conditions. It may reduce the amount of information required for
scheduling decisions when system load or communication is high.
Most
models assume that the system is fully
connected and that every processor can communicate, perhaps in a number of
hops, with every other processor although generally, because of communication
latency, load scheduling is more practical on tightly coupled networks of
homogeneous processors if the workload involves communicating tasks. In this
way also, those tasks might take advantage of multicast or broadcast features
of the communication mechanism.
Processor
allocation strategies can be non
migratory(non preemptive) or migratory(preemptive).
Process migration involves the transfer of a running process from one host to
another. This is an expensive and potentially difficult operation to implement.
It involves packaging the tasks virtual memory, threads and control block, I/O
buffers, messages, signals and other OS resources into messages which are sent
to the remote host, which uses them to reinitiate the process. Non migratory
algorithms involve the transfer of tasks which have not yet begun, and so do
not have this state information, which reduces the complexities of maintaining
transparency.
Resource
queue lengths and particularly CPU queue
length are good indicators of load as they correlate well with the task
response time. It is also very easy to measure queue length. There is a danger
though in making scheduling decisions too simplistic. For example, a number of
remote hosts could observe simultaneously that a particular site had a small
CPU queue length and could initiate a number of process transfers. This may
result in that site becoming flooded with processes and its first reaction
might be to try to move them elsewhere. As migration is an expensive operation,
we do not want to waste resources (cpu time and communication bandwidth) by
making poor choices which result in increased migration activity.
A load distributing algorithm has,
typically, four components:- transfer, selection, location and information
policies.
Transfer
Policy
When
a process is a about to be created, it could run on the local machine or be
started elsewhere. Bearing in mind that migration is expensive, a good initial
choice of location for a process could eliminate the need for future system
activity. Many policies operate by using a threshold. If the machine's load is
below the threshold then it acts as a potential receiver for remote tasks. If
the load is above the threshold, then it acts as a sender for new tasks. Local
algorithms using thresholds are simple but may be far from optimal.
Process
Selection Policy
A
selection policy chooses a task for transfer. This decision will be based on
the requirement that the overhead involved in the transfer will be compensated
by an improvement in response time for the task and/or the system. Some means
of knowing that the task is long-lived will be necessary to avoid needless
migration. This could be based perhaps on past history.
A
number of other factors could influence the decision. The size of the task's
memory space is the main cost of migration. Small tasks are more suited. Also,
for efficiency purposes, the number of location dependent calls made by the
chosen task should be minimal because these must be mapped home transparently.
The resources such as a window or mouse may only be available at the task's
originating site.
Site Location
Policy
Once
the transfer policy has decided to send a particular task, the location policy
must decide where the task is to be sent. This will be based on information
gathered by the information policy.
Polling
is a widely used sender-initiated technique.
A site polls other sites serially or in parallel to determine if they are
suitable sites for a transfer and/or if they are willing to accept a transfer.
Nodes could be selected at random for polling, or chosen more selectively based
on information gathered during previous polls. The number of sites polled may
vary.
A receiver-initiated scheme depends on
idle machines to announce their availability for work. The goal of the idle
site is to find some work to do. An interesting idea is for it to offer to do
work at a price, leaving the sender to make a cost/performance decision in
relation to the task to be migrated.
Information
Policy
The
information policy decides what information about the states of other nodes
should be collected and where it should be collected from. There are a number
of approaches:
Demand Driven
A node collects the state of
other nodes only when it wishes to become involved in either
sending or receiving tasks, using sender initiated
or receiver initiated polling schemes.
Demand driven policies are inherently adaptive and
dynamic as their actions depend on the
system state.
Periodic
Nodes exchange information at
fixed intervals. These policies do not adapt their activity to
system state, but each site will have a substantial
history over time of global resource usage to
guide location algorithms. Note that the benefits of
load distribution are minimal at high
system loads and the periodic exchange of
information therefore may be an unnecessary
overhead.
State-Change Driven
Nodes disseminate state
information whenever their state changes by a certain amount. This
state information could be sent to a centralised
load scheduling point or to peers.
Design Issues
for Processor Allocation Algorithms
The
major design decisions can be summed up as follows:
Deterministic
versus Heuristic
Deterministic
algorithms are appropriate when everything about process behaviour is known in
advance. If the computing, memory and communication requirements of all
processes can be established, then a graph may be constructed depicting the
system state. The problem is to partition the graph into a number of subgraphs
according to a stated policy so that each subgraph of processes is mapped onto
one machine. This is achieved subject to the resource constraints imposed by
each machine.
Heuristics
refer to principles used in making decisions when all possibilities cannot be
fully explored. For example, consider a site location algorithm where a machine
sends out a probe to a randomly chosen machine, asking if its workload is below
some threshold. If not, it probes another and if no suitable host is found
within N probes, the algorithm terminates and the process runs on the
originating machine.
Centralised
versus Distributed Algorithms
Centralised
algorithms gather all information to a single location before reaching a
decision. Although better decisions can be made with access to global
information, the approach is not scaleable because it generates a bottleneck
and is not as resilient to failure as decentralised algorithms. A hierarchical
organisation is one approach to decentralisation.
Optimal versus
Suboptimal Algorithms
Optimal
solutions require extensive system information and devote significant time to
analysis. A study of the complexity of this analysis versus the success of
solutions might reveal that a simple suboptimal algorithm can yield acceptable
results and will be easier to implement.
Deterministic
algorithms impose excessive costs on all modules within the policy hierarchy and
are not scaleable, but can achieve optimal results. Heuristic techniques are
invariably less expensive and often demonstrate acceptable but suboptimal
results.
Local versus
Global Algorithms
When
a process is being considered for migration and a new destination is being
selected, there is a choice between allowing this decision to be made in
isolation by the current host or, to require some consideration of the status
of the intended destination. It may be better to collect information about load
elsewhere before deciding whether the current host is under greater pressure or
not.
One
globally continuous technique, is to associate an 'income' with each process so
that the larger this value is relative to other processes at this site, the
greater the percentage of processor cycles received. This income is adjusted
based on the operational characteristics revealed by the process to the
operating system. For heavily loaded sites the percentage of processor cycles
received makes poor economic sense and processes migrate to where they can
obtain more cycles per current income.
Sender
Initiated versus Receiver Initiated Algorithms
Maintaining
a complete database of idle or lightly loaded machines for migration can be a
challenging problem in a distributed system. Various alternatives to this have
been proposed.
With
sender initiated schemes the overloaded machine takes the initiative by random
polling or broadcasting and waiting for replies. With receiver initiated
schemes an idle machine offers itself for work to a group of machines and
accepts tasks from them.
In
some situations a machine can become momentarily idle even though on average it
is reasonably busy. As discussed earlier, care must be taken to coordinate
migration activity so that senders do not capitalise on this transient period
and send a flood of processes to this node. One approach is to assign each site
a local load value and an export load value. The local load value reflects the
true state of the machine while the export load value decreases more slowly to
dampen short-lived fluctuations.
Process
Migration
Although
it is difficult to implement, a mechanism for process migration broadens the
scope and flexibility of load sharing algorithms. Decisions on process to
processor assignment can be dynamically reconsidered, in response to changing
system conditions or user or process preferences. Tasks can be preempted and
moved elsewhere rather than being statically assigned to a host until
completion. Some of the motivating situations where such a mechanism could be
useful are given next.
Load Balancing
Empirical
evidence from some studies has shown that often, a small subset of processes
running on a multiprocessor system often account for much of the load and a
small amount of effort spent off-loading such processes may yield a big gain in
performance.
Load sharing algorithms avoid idle time
on individual machines when others have non-trivial work queues. Load
balancing algorithms attempt to keep the work queues similar in length
and reduce average response time, but are clearly more complex as they have
more global and deterministic requirements. Commonly, load level is defined as
CPU utilisation of hosts in a catchment area. A more elaborate index could be
developed based on the contention for a number of resources and which employed
a smoothing or dampening technique. An important metric of the load balancing
policy is the anticipated residency period required by the process, to avoid
useless and costly migrations. A competitive
algorithm allows a process to migrate only after it executes for a period
of time that equals or exceeds its predicted migration time. This idea is based
on the probabilistic assumption that a process will exhibit a 'past-repeat'
execution pattern. This approach has been shown to be simple to implement,
provides an adequate method of imposing the residency requirement and adapts
well to the current workload state of the participating processors.
Communication Performance
Network
saturation can be caused by heavy communication traffic induced by data
transfers from one task to another, residing on separate hosts. The
interprocessor traffic is always the most costly and the least reliable factor
in a loosely coupled distributed system. As a result of the saturation effect,
the incremental increase in computing resources could actually degrade system
throughput.
This
situation can occur when processes perform data reduction on a volume of data
larger than the process's size, e.g. a large database. In these circumstances, it
may be advantageous to move the process
to the data, rather than using network bandwidth, especially between
geographically distant parties. The principle of spatial locality
indicates that strongly interacting entities should be mapped in close proximity.
In other words, the system must endeavour to match the logical locality with the
physical locality.
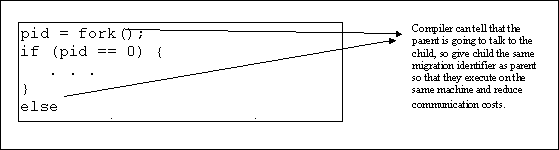
It
has been observed that for many parallel and distributed computations that it
may be possible to determine communication loads at compile time and use this
information to guide migration at
runtime by including additional information in the process descriptor. To
reduce IPC costs, the compiler may analyse the structure and phases of
communication and suggest which processes should reside on the same machines.
One technique is to associate a migration identifier with each process and to
keep processes with equivalent migration identifiers on the one machine. A
second technique (capitalising on compiler intelligence) known as eager
migration can be used when it is known that a process A will soon
migrate to B's location. Portions of process A may be piggybacked, in advance,
on other messages bound for the same destination, to reduce migration time.
Fault Tolerance
Long
running processes may be considered as valuable elements in any system because
of the resource expenditure that has been outlaid already. Failure of mature
processes becomes important if time and resources are precious and cannot be
reassigned. Long running processes are particularly susceptible to transient
hardware faults and may be worth rescuing by rapid evacuation. That is, a policy could be adopted which
prioritised migrations from a machine about to shut down, based on the order of
their computational value to the system. Such policies would require a high
degree of concurrency within the migration mechanism to abandon a site quickly.
Application Concurrency
The
divide and conquer, or crowd approach to problem solving decomposes a problem
into a set of smaller problems, similar in nature, and solves them separately.
The partial solutions are combined to form a final solution to the original
problem. The smaller problems may be solved independently and concurrently in
many cases using a copy or subset of initial data, exemplified by a tree or
graph structure. Evaluating a game position, multiplying matrices or finding
shortest paths can be performed in this way. Applications exhibiting high
concurrency with little inter-task communication can benefit from these tasks
being distributed to execute with true concurrency, on separate hosts.
Processor pool architectures are particularly suited to these applications
where migration may occur before processes establish locally.
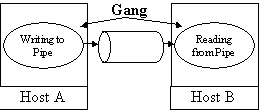
Another
situation related to concurrency is gang
scheduling. Consider the situation where a process communicates via a pipe
with another process and one of the processes has been chosen for migration. If
the processes reside on different sites, then their relative scheduling can impede
concurrent performance to the extent that they may benefit more from residing
on the same site.
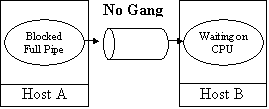
To
demonstrate this, one process may be executing while the other is in a ready
queue. The executing process fills the communication buffers and must then wait
until they are emptied by the other process before being able to proceed. When
the other process is scheduled it may process the communication buffers and
then must wait until the other process is able to supply more data. This lock
step execution may impede performance of the application and makes bulk
transfers impossible. If both processes were scheduled in coordination using
gang scheduling on the separate hosts, both consumer and producer could operate
concurrently. If gang scheduling is not employed then perhaps no real
concurrency is achieved and the network traffic is incurred for nothing.
The
opposite is true for client/server interactions, where a client is the
triggering process and the server is the reactive process. There may be no
potential benefit to an application to be gained from allocating servers and
clients to separate processors apart from the likelihood that services may be
available on faster machines and are distributed for availability and performance.
Miscellaneous Reasons
Generally,
migration makes it difficult to maintain transparency. In some circumstances
though it can assist in this objective. For example, a resource may not be
accessible remotely, or there may be insufficient resources available locally.
Special purpose hardware such as array processors or graphical devices may be
far too inefficient to use if the process was remote. A machine may have
insufficient memory space for a new task. Without migration, these tasks would
have to be terminated or execute very inefficiently.
Some
systems allow both automated migration and application directed migration. It
is interesting to allow a process to control its own migration activity. In
addition, a process may be able to lock itself to a particular machine to
prevent automated migration, but this means it must be aware of machine names.
This may be to facilitate a user's security preference.
Other
systems consider ownership of user workstations to be important and users
prefer not to have foreign processes executing there when they are using their
workstation. The load average daemons can detect when a user returns
(interactive activity) and can evict processes using migration and send them
home or elsewhere.
Migration
Design Interdependencies
The
migration mechanism provides an interface between the machine independent
policy algorithm and the machine dependent process model of a specific kernel.
For reasons of efficiency, flexibility and economy of implementation, the
mechanism operates in close association with other kernel modules to obtain
various statistical information and to manipulate local and remote kernel
structures. Other aspects of system design therefore, can complement
implementation strategies for process migration or make them unworkable.
Levels of Transparency
Transparency
considerations influence the design of all subsystems within a physically
distributed domain. Transparency is analogous to usability and enhances
psychological acceptability of the operating system's interface. Even in
centralised systems, I/O device characteristics are hidden from processes by
encapsulating them in generic I/O abstractions. For process migration, there
are a number of dimensions to transparency which combine to simplify implementation
of relocatable distributed applications.
Access
Transparency
Interface
consistency is a general I/O design feature but often, to control the
functional peculiarities of some devices, specialised operations must be
provided. This may restrict access in certain situations to the locality
supporting special resources. For general categories of I/O devices, the
interface should be independent of location and must not create a distinction
between local and remote resource access.
Location
Transparency
The
use of resource location identifiers, supplied as interface parameters must be
avoided. With client/server relationships and the dynamic nature of
process/host mapping, the migration of a process can cause a detachment at the
application layer. Recovery may ensue, where a client may try to relocate a
migrated server when communication fails, but this places an extra burden on
the design of distributed applications.
Control
Transparency
Control
Transparency refers to automatic operating system control of process/host
configurations. Control is independent of the mechanism and resides in a policy
algorithm outside the kernel and is directed at specific system tuning
strategies. This activity must occur without affecting the execution
environment of any running processes.
Execution
Transparency
Execution
transparency affects the correct and continuous operation of the migrant
specifically for the periods during and subsequent to a migration action.
Freezing the migrant for an extensive period magnifies the probability of
missing events, which subsequently can result in nondeterministic operation.
The kernel must implement buffering and modify communication protocols to
accommodate and tolerate delays which are generated by system activity. If
migration is automatic, erratic response times can develop from seemingly
'transparent' system activity, resulting in user dissatisfaction. To avoid
this, the mechanism must be designed efficiently for speed of transfer. In the
event of failure or process crash, the owner of the process must be able to
retrieve the exception information or debug the process whether it is local or
remote. It is not always possible or desirable to shield all details of
transparent execution from the owner.
Residual Dependencies
Processes
are dependent on their host for access to system calls, physical resources such
as memory and process interaction. Some kernel designs, such as unmodified
Unix, make it impossible to detach a process from the complex interdependencies
of its current environment. Even with kernels that do facilitate migration, the
relocation of a process may not completely liberate the former host from
maintaining some responsibility for it, therefore a residual dependency remains
for some kernel functions. Residual dependencies can be deliberate in an effort
to improve the migration mechanism performance. However, the more hosts that a
process depends on for its execution reduces reliability.
Communication
Dependency
When
a process changes location, existing interactions must be rerouted. This is the
most prevalent form of dependency. A number of methods for solving this have
been proposed.
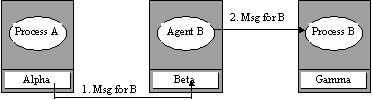
Alias responds with
destination of migrant to guide retransmission
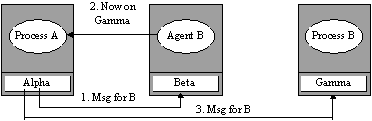
Alias relays message to
expected location of B Agent broadcasts B's new
location for a fixed time and then exits
(a) A client driven scheme where the kernel installs a light
weight alias process at the original location which responds to client
interactions indicating that the process has migrated. The communication
facility, on behalf of the client, must relocate the process with a broadcast
and update caching information at the source kernel. Essentially, the
communication information is used as a hint rather than as a definite address.
The communication protocol uses the hint (or cached location information) by
default for efficiency, but is able to deal with invalid hints transparently by
operating a relocation protocol. Relocation protocols do not execute often as
migration is also infrequent.
(b) A message
forwarding scheme where a more intelligent agent process relays incoming
messages. Continual redirection can be eliminated if the agent sends update
information to source kernels as they reveal themselves.
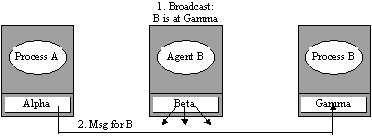
(c) A server driven scheme where an agent repeatedly broadcasts
the migrant's location for a fixed duration before self termination. A
variation of this approach is to maintain information on all kernels which have
interacted with the migrant and send them update messages.
(d) Associate a home node with every process through which it can
always be located.
Address Space
Dependency
The
longer a process is frozen, awaiting establishment elsewhere, greater is the
chance of failure. The transferal of the migrant's address space is the
bottleneck of the operation. By leaving the address space (or part of it)
behind, the process can be reestablished more quickly. The address space may be
copied on reference from the original host as required by the process. This
involves integrating the migration mechanism more closely with virtual memory
management and the interprocess communication mechanism.
Execution
Dependency
Some
systems based on modified Unix kernels employ the concept of a home node which
deals with all kernel specific operations. The purpose is to ensure complete
transparency for the process when it moves from the environment of one kernel
to another. A subset of environment dependent kernel calls are forwarded by the
current host to the home node for execution. The home node may also forward any
signals or messages to its dependant. Processes which make extensive use of
their home kernel will incur performance penalties.
Concurrency
Simultaneous
migrations introduce consistency difficulties among kernels, especially those
managing connection oriented links where both ends of the link are changing.
However, a mechanism with limited concurrency would be simpler to implement but
could limit the flexibility of policy algorithms.
Three
obvious levels of concurrency are conceivable:
One migration
per network guarantees that the peers of the migrant are stationery, so message
redirection is routine. Arbitration will be required to sequence migration
activity. This degree of concurrency is not adequate for rapid evacuation of a
failing host or to implement eviction properly. The arbitration mechanism can
become a bottleneck to scalability.
Rapid
evacuation becomes possible with unlimited migration but generates
the extreme of kernel inconsistency and can lead to thrashing where processes
are continually relocated due to rapidly changing load conditions at each site.
Without a well directed policy to control migration, mechanism stability can be
affected and flooding or abandoning of various sites is possible.
One migration
per machine can mitigate the problems of flooding and simplify kernel state but
does not cater for rapid evacuation.
Processes migrate
concurrently from Alpha and Gamma to Beta Thrashing results where
processes must be moved on again
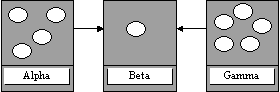
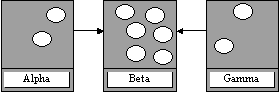
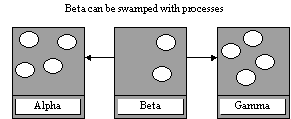
Migration Protocol
The
migration protocol describes the sequence of events that occur once a process
is selected for relocation. The protocol decides when the migrant is frozen and
over what duration and at what point the migration is committed. It must
marshal, transfer and demarshal process state and manage any environmental
events that occur while the process is disabled. Some protocols may anticipate
failure and build recovery actions.
There
are three clear phases within a migration protocol, namely negotiation,
transfer and establishment.
Negotiation
The
bulk of negotiation procedures are carried out by the policy modules which
select a candidate for migration and select a new host. Further negotiations by
the mechanism are necessary to check that low-level resources are available
within the structures of the remote kernel. A remote process descriptor, memory
segments and communication resources must be allocated in preparation for
transfer. Again this is a reason why the mechanism is best implemented as a
thread operating in kernel space.
Transfer Phase
The
transfer phase generally takes the longest and is the focus of most of the
experimental techniques. Process state comprises three basic components which
may be shipped separately in arbitrary order, or packaged together. These
elements are, the process descriptor, the address space and messages (or
signals) which occur while suspended. The process must be suspended before its
descriptor is transferred and then reactivated when the minimal amount of state
has been established. Long freeze times complicate IPC delivery semantics.
Short freeze times require leaving residual dependencies and can cause future
unpredictable delays which may affect real time response requirements. An interesting
approach which allows short freeze times and avoids residual dependency is to
precopy the bulk of the address space to the new site before the process is
frozen. The remaining dirty pages can be transferred with the process
descriptor.
Establishment Phase
The
final phase tidies up the transfer and restores resource connections before
returning the process to ready status. Once responsibility has transferred, the
mechanism reclaims any low-level resources and real memory released by the
migrant and flushes message buffers by retransmitting them or perhaps,
depending on IPC semantics, allowing them to timeout and be retransmitted by
the sender. The protocol may fail at any stage due to network or machine
failure and rescuing processes under all circumstances requires complex
recovery protocols. This can be offset by transferring responsibility for the
migrant as late as possible in the protocol.
Statistics
Migration
Policy is driven by the availability of information relating to resource
utilisation locally and globally. A wide range of policies must be supported to
suit the spectrum of behaviours exhibited by certain types of distributed
application. Many statistics can be gathered from kernel accounting structures
by periodic or event driven sampling. Simplistically, processes must be
categorised as being CPU intensive, memory hungry, having high disk capacity or
being involved in copious (possibly long distance) communication. From these
relative indicators it is possible to design a weighted function to compute an
overall load index to drive a particular policy. The relative power of various
resources may be included in the equation. Mean response times, turnaround
times and standard deviations for processes must be maintained to compare the
effect of dynamic reconfigurations and to tune the host index. The resources
required for the migration operation itself must be minimised and so an
estimate of the size of a process's dirty address space and current system
network throughput could be factors in choosing a migrant. Perhaps an ordered
list of desirable migrants could be maintained to simplify the quick selection
of processes to send off to sites which seek work.
In
short, considerable CPU and communication resources will be required by a
migration mechanism to provide adequate information for the implementation of
administrative policies.
Load
Scheduling Algorithms
Graph Theoretic Algorithms
Graph
theoretic algorithms refer to systems of processes with known computation and
communication costs. The idea is to perform the assignment of processes to
processors to maximise resource utilisation to achieve either maximal
concurrency or minimal communication. This has been shown to be NP-complete so
heuristic approaches are used which, for example, could focus on tightly
coupled clusters which have little interaction with other clusters.
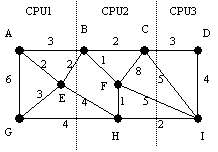
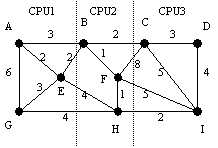
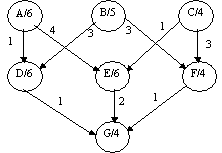
Example:
Tasks A..I are assigned to three CPUs. The edges of the graph which cut the
dotted lines represent network communication cost units.
Network Traffic is 30
units Network Traffic is 28
units
The
precedence process model is suitable
for analysing the task scheduling of a user application where precedence
constraints among tasks are explicitly specified in the program. The primary
objective in assigning tasks to processors is to achieve maximal concurrency
for task execution within the program. The nodes contain information about task
length and the edges indicate the number of message units to be communicated to
each successor task.
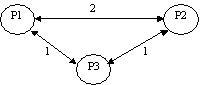
The
communication system model can be
used to characterise the underlying architecture on which the tasks are to be
mapped, showing unit communication costs between two processors. Intraprocessor
communication is assumed to be negligible. For various assignments of tasks to
processors the communication cost is easily computed from these models.
Without
considering communication overhead, consider a simple greedy heuristic, used by
the List Scheduling (LS) strategy:- No processor remains idle if there are some
tasks available that it could process. For the precedence graph of the previous
page, the resulting schedule would be as follows:-
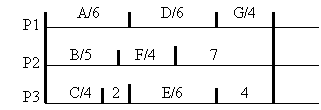
The
total completion time is 16 units. The critical path of the graph is the
longest execution path and this defines the lower bound on completion time. It
is useful to compare the performance of our heuristic approach against this and
we see it is optimal in this case.
With
communication overhead, the Extended List Scheduling algorithm (ELS) first
allocates tasks to processors by applying LS. The communication costs are then
computed from the unit interprocessor costs and the number of message units
between tasks. The result for ELS would be as follows
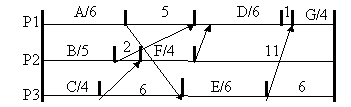
The
total completion time is 22 units. The ELS strategy is not optimal because the
scheduling decision was made without anticipating the communication. Consider
the Earliest Task First strategy (ETF) where the earliest schedulable task is scheduled first. Tasks A,B,C are schedulable
immediately and so are scheduled onto processors 1,2,3. If communication costs
are taken into account, task E becomes schedulable earliest on processor 1 at
time 6, replacing the original choice of task D which will not be schedulable
until time 8 at the earliest. Task F becomes schedulable on processor 2 at time
7, so task D is assigned to processor 3 at time 8. The earliest time task G can
be scheduled is on processor 3 at time 14. The total completion time is 18
units.
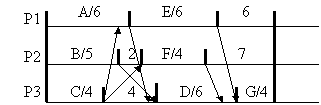
The
earliest schedulable time calculation is derived below:
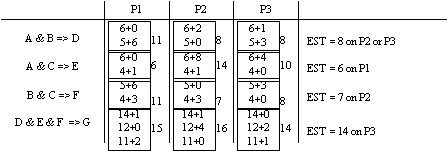
The
communication process model is
suitable for analysing processes without precedence constraints but that are
related by a need for communication. The processes do not have explicit
completion times but have a cost associated with communication between them.
The edges of the communication process graph (G) indicate the relative cost of
communication units. There is also an execution cost which is a function of the
processor to which the process is assigned.
The
scheduling of various system processes/services which have been created independently
fits well to this model. The primary objective is to minimise the overall cost
of execution and communication.
More
formally, a communication cost ci,j(pi, pj)
between two processes i and j executing on separate processors pi
and pj is proportional to the weight of an edge connecting i and j.
The
cost is negligible if i=j.
The
execution
cost ej(pi) is the cost of executing process j on
processor i.
The
objective is to find an optimal assignment of processes to P processors with
respect to the following function:-
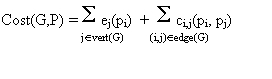
This
general problem is NP-complete except for a few restricted cases where
polynomial time solutions exist. It is complex because the objectives of
minimising computation and communication costs often conflict and there maybe other
allocation constraints.
Example:
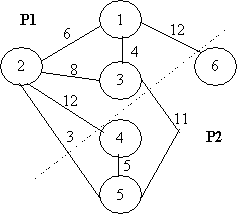
Consider
a system of 6 processes (1..6) to be allocated to 2 processors (A and B). A and
B are different processors and so the execution of a process on either has a
different cost. The graph indicates the cost of communication between two
processes if located on different processors.
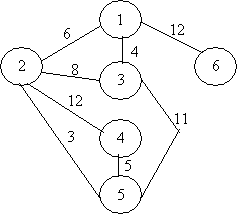
We
can partition the graph with a line that cuts some edges, giving us two
disjoint subgraphs, one for each processor. The edges intersected by the cut is
called the cut set and the sum of the weights of these edges represents the
total interprocess communication cost. Minimising the communication cost alone
is trivial as we could map all processes to one processor, but obviously we may
have to satisfy other constraints such as maximum processes allowed per
processor or that some processes must be mapped to certain processors, or that
the loads on each processor should be equal.
In
our 6 process, 2 processor example, let's say that the execution costs of each
process on each processor are given by the following table:-
|
Process |
Cost on A |
Cost on B |
|
1 |
5 |
10 |
|
2 |
2 |
infinity |
|
3 |
4 |
4 |
|
4 |
6 |
3 |
|
5 |
5 |
2 |
|
6 |
infinity |
4 |
Note
that process 6 is restricted to run on processor A and process 2 must run on
processor B.
The
minimum cost cut is given below:-
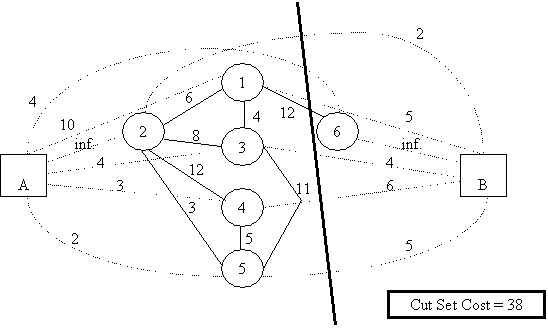
In
the diagram, two new nodes representing processors A and B are included and
dashed edges from each of these nodes to all of the processes. The dashed edges
from processor A are weighted with the amount of execution cost that the
corresponding process would incur on processor B. This is because if the cut
intersects one of these edges then that process has been assigned to processor
B and the cost of executing it on B would apply. Similarly, the dashed edges
from processor B are weighted with the amount of execution cost that the
corresponding process would incur on A.
It
is difficult to generalise the problem beyond two processors. One heuristic
approach is to divide the problem of optimising both communication and
execution costs into two independent phases. We can merge processes with higher
interprocess communication into clusters, to be scheduled onto a single
processor to minimise communication costs. The clusters would then be scheduled
onto the processor which offered the minimal execution time for the cluster.
We
could invent a threshold for communication between processes, which if crossed
causes them to be clustered. We could also invent a threshold cost of execution
for the entire cluster (to prevent burdening of a single processor) which if
exceeded forces the cluster to be divided among a number of processors or
assigned away from the minimal cost processor.
In
the example, if we use a communication threshold of 9 we can identify 3
clusters (2,4), (1,6), (3,5). (2,4) must be mapped to A because of 2, (1,6)
must be mapped to B because of 6. (3,5) could be mapped to either A or B.
Assigning to B incurs higher communication cost but lower execution cost.
Assigning
to A results in an execution cost of 17 on A and 14 on B and communication cost
of 10. The total cost therefore is 41, slightly higher than the optimal.
Dynamic Algorithms
The
precedence process model and communication process model both assume some prior
knowledge about process behaviour. This allows us to make centralised and
static scheduling decisions which act to maximise application concurrency or
minimise execution and communication costs.
The
disjoint process model is used when
this prior knowledge about process interaction is not available. Processes are
scheduled as if they were independent of one another with perhaps the
objectives of maximising resource utilisation and system throughput and being
fair to user processes.
The
scheduling algorithms can be dynamic using migration to relocate processes as
required. Various approaches to this have already been discussed.
A
sender-initiated nonpreemptive distributed heuristic algorithm employing
migration is given below. The sender sends out a limited number of probes
searching for an idle host. If one is found then the process is migrated. If no
site is idle, but sites with shorter queues exist then the process is sent to
the one with the shortest queue. Otherwise the process is executed locally.
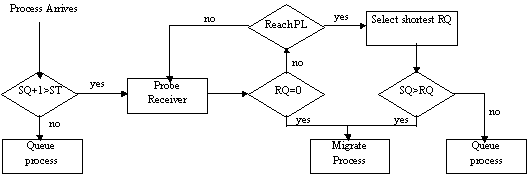
SQ:
Sender's queue length RQ:
Queue length of polled receiver
ST:
Threshold for migration
PL:
Max Probes by Sender
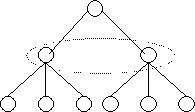
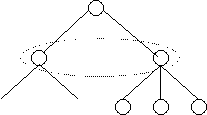
Hierarchical Algorithms
![]() A hierarchical processor
structure places some processors in control of groups of processors beneath
them in the hierarchy. Hierarchical structures scale well by simply increasing
the number of levels in the hierarchy. Each processor keeps an estimate of the
number of subordinate resources available to it. Tasks can be created at any
level in the hierarchy. If the processor receiving the request decides that the
resources available to it are insufficient it can pass the request up to its
parent. This continues until a level with sufficient processing resources is reached.
At that point the controlling processor divides the task and assigns its parts
to processors immediately below it in the hierarchy. These in turn pass out the
work among their subordinates until the wave of allocation hits the bottom of
the hierarchy. The number of actual processing resources assigned is passed up
the hierarchy to allow each processor to adjust its estimate of available
resources. Of course, this is greatly complicated if a number of allocation
requests are in progress at the same time, as workload estimates may be out of
date. Another difficulty is developing a means of replacing a failed processor,
perhaps by electing a subordinate to the role, or instead by using a group of
processors at each level to make scheduling decisions.
A hierarchical processor
structure places some processors in control of groups of processors beneath
them in the hierarchy. Hierarchical structures scale well by simply increasing
the number of levels in the hierarchy. Each processor keeps an estimate of the
number of subordinate resources available to it. Tasks can be created at any
level in the hierarchy. If the processor receiving the request decides that the
resources available to it are insufficient it can pass the request up to its
parent. This continues until a level with sufficient processing resources is reached.
At that point the controlling processor divides the task and assigns its parts
to processors immediately below it in the hierarchy. These in turn pass out the
work among their subordinates until the wave of allocation hits the bottom of
the hierarchy. The number of actual processing resources assigned is passed up
the hierarchy to allow each processor to adjust its estimate of available
resources. Of course, this is greatly complicated if a number of allocation
requests are in progress at the same time, as workload estimates may be out of
date. Another difficulty is developing a means of replacing a failed processor,
perhaps by electing a subordinate to the role, or instead by using a group of
processors at each level to make scheduling decisions.
![]()
![]()