Programming Models
Parallel programming models are generally categorized by how memory is
used. In a shared memory model each process accesses a shared address space,
while in the message passing model an application runs as a collection of
autonomous processes, each with its own local memory. In the message passing
model processes communicate with other processes by sending and receiving
messages. When data is passed in a message, the sending and receiving processes
must work to transfer the data from the local memory of one to the local memory
of the other.
Message passing is used widely on parallel computers with distributed
memory, and on clusters of servers. Message passing is implemented on most
parallel platforms and the model makes minimal assumptions about underlying
parallel hardware. Message-passing libraries exist on computers linked by
networks and on shared and distributed memory multiprocessors.
Message Passing Model
The Interprocess communication (IPC) mechanism is central to the design of parallel and distributed systems. Such systems depend on computer networks for the communication of data and control information and require security, high performance and reliability from the mechanism. In addition, all process coordination depends on interprocess communication. The IPC facility must hide the distinction between local and remote processes and provide a natural and simple interface to communication which aids the modular structuring of distributed applications.
The performance
of point-to-point communication is measured in terms of total transfer time.
The total transfer time is defined as
total_transfer_time = latency + (message_size/bandwidth)
where
|
latency |
|
Specifies the time between the initiation of the data
transfer in the sending process and the arrival of the first byte in the
receiving process. |
|
message_size |
||
|
|
|
Specifies the size of the message in Mbytes. |
|
bandwidth |
||
|
|
|
Denotes the reciprocal of the time needed to transfer a
byte. Bandwidth is normally expressed in Mbytes per second. |
Low latencies and
high bandwidths lead to better performance.
Network Protocols
Computer Networks differ in their topology, transmission speeds and protocols for packaging data and are susceptible to errors in transmission. Messages to be delivered by the network are broken into data packets, typically between a hundred and a few thousand bytes in size and routed by network protocols to their destination. Error detection/correction information (Cyclic Redundancy Check) is bundled redundantly with each packet to ensure the receiver knows if a transmission error occurred enabling corrective action. Error detection is sufficient where data is easily retransmitted, but error correction is more suited to long haul transmissions or to real time continuous stream transmissions required perhaps by multimedia applications.
The ISO OSI reference model organises the IPC facility into a hierarchy of functional layers, each of which provides enhanced communication functionality and reliability than the services of the layer beneath it.
At the bottom of the hierarchy, media errors are corrected by the data link layer protocol which uses timeouts, acknowledgments and retransmission to detect and correct packet loss between two directly connected nodes. The data link layer passes packets to the network layer above. The packets of a message may delivered upwards in order by sequence number (at the expense of latency) or passed up unordered.
The network layer is responsible for routing packets through the network. Messages may have to travel several hops in a point to point network. The network layer uses the data link layer to send a packet point to point to its peer on the next hop point. The peer network layer will then forward the packet onwards and so on. Routing decisions can be made independently for every packet (datagram/connectionless service) or once for a collection of packets so that all packets follow the same route (connection-oriented). Connectionless network layer service does not guarantee that packets are delivered in the order sent whereas a connection-oriented network layer service usually does.
Network layer protocols deliver data between hosts, not processes. The transport layer is responsible for delivering data end to end between processes. It packages messages into suitable units for transmission by the network layer and assembles the incoming packets from the network layer into message units. Processes use the API of the transport layer to send and receive messages. It may run over a connection-oriented or connectionless network service and offers a variety of reliability levels to user processes.
Properties of Communication Protocols
Networks exhibit failure and packets get lost or corrupted. As long as the faults are transient, they can be corrected using feedback protocols. If the fault is permanent, such as a broken or disconnected cable, the communication protocol cannot be made reliable. A client cannot distinguish if a server went down from one that has become disconnected. Furthermore, the client cannot find out if the server has received the request and whether it has started or finished carrying out the work.
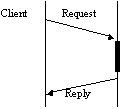
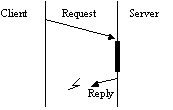
Server Client Correct Operation Server Crash Communication Failure

![]()
We can use more restricted failure models to make it easier to construct fault tolerant protocols. For example, if we assume communication is reliable but processes are not, then we can now interpret failure as being a server crash. The protocol must then ensure a reliable recovery for this situation. When a server comes back up, clients can continue perhaps by retransmitting the last unanswered request. What if the server has carried out the request already, but failed to send the reply before crashing?
If the server remembers this, it could recompute the reply and send it to the client. Such protocols require servers to use stable storage and atomic transactions.
However, a large class of applications which don't use these methods can suffer server crashes and may forget requests in progress at the time of the crash. The server may restart from an initial boot state unaware of uncompleted requests. Exactly once message delivery semantics may be difficult to achieve. Other semantics of delivery may be sufficient for some applications.
At-least-once protocols deliver messages exactly once in the absence of failures but may deliver more than once when failure occurs. Such protocols work when requests are idempotent, i.e. repeatable.
At-most-once protocols operate in the context of a session during which two processes maintain a protocol state. Whenever state is lost the session is discarded. The processes must agree on what is the current session and that no messages sent in one session are received in another.
Choosing session names is not as easy as it appears. When a process crashes it may forget everything including the name of the current session. A common way is to use timestamps as part of the session identifier or use sufficiently sparse random numbers.
Crashes are rare occurrences, and protocol designers should design optimally for the normal case where crashes don't occur. The simplest scenario is a two message exchange protocol. The client sends a request and the server subsequently sends a reply. A response sent to a client after complete execution of a request is a positive indication that the request was carried out without failure. However, the reverse does not hold, that is the server does not know if the reply got through.
Basic Coordination Problem
It is not possible to achieve agreement on success of the request both at the client and server at the same time in the presence of faulty links. This is a fundamental coordination problem for which no protocol solution exists.
Proof: Any protocol that solves the problem is equivalent to one in which there are rounds of message exchange. For example, A sends to B, B sends to A, A sends to B etc. Say a protocol exists that solves the problem using the fewest rounds where m is the last message of the protocol. Say m is sent by A.
The agreement ultimately reached by A cannot depend on whether m is received by B because its receipt can never be learned by A. So A's choice does not depend on m. The agreement ultimately reached by B cannot depend on m because it must reach the same agreement as A even if m is lost. Therefore m is superfluous, so a shorter protocol can be constructed. However, this contradicts our original assumption that we selected the shortest protocol.
The conclusion here is that additional acknowledgments of messages received or messages not received can be useful to enhance performance of the protocol but no amount of complexity in the protocol between a client and server process can ever guarantee that the client is aware that the request was carried out correctly and at the same time the server is aware that the client received the reply.
Interprocess
Communication Middleware
All interprocess communication is based on the exchange of packets of information. There are a number of levels of abstraction built on this mechanism for simplifying different forms of interaction.
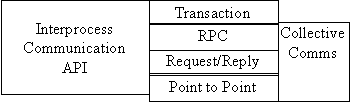

Point to Point Message Passing is the lowest level of abstraction for an application programmer. It is also the most flexible form of communication. There is no notion of a connection between two communicating processes. Message passing services normally offer two generic primitives for message passing:-
Send(destination, message)
Receive(source, message)
where source and destination may be a process name, a link, a mailbox or a port.
Message Addressing
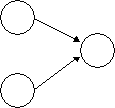
To communicate using the process name requires that it be unique. This can be achieved by concatenating the network host address with a uniquely chosen identifier on the creating host. The scheme only provides for one bidirectional direct communication path between any pair of processes.
The scheme is symmetric as both sender and receiver explicitly name the interacting process.
It may be required to receive messages from unknown sources in which case the destination field becomes an input variable, indicating the source process which sent the message. This scheme is asymmetric.
Links can be used to establish a number of unidirectional channels between processes. Messages sent to a link are mapped to a network communication path and delivered to the remote host which maps the message to the input link on the remote process. Using (process name, link number) pairs for addressing provides multiple channels of direct communication between processes.
![]()
![]()
Symmetric process name Asymmetric process name Links
Sometimes, indirect communication may be preferred. The sending process is not particularly interested in the identity of the receiving process. This style of communication can be achieved with shared mailboxes. This is an indirect communication scheme that offers the possibility of multi-point and multi-path communication.
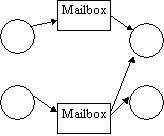
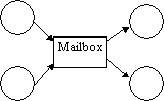
Multipoint
Communication Multipoint and
Multipath Communication
A port is a special type of mailbox which operates as a FIFO queue of messages maintained by the OS kernel. Ports are created by user processes (using system calls) and can be associated with ownership and access capabilities. Ports and mailboxes provide a bidirectional and indirect means of interprocess communication.
The Unix system uses a high level socket interface for communication which is based on the concept of ports.
Message Synchronization and Buffering
When sending a message to a remote destination, the message is passed to the sender's system kernel, which transmits it to the communication network and eventually the message reaches the remote system kernel which delivers it to the destination process.
Synchronization occurs at several points.
Network sender receiver message ack
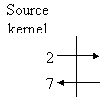
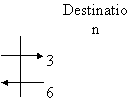
1. Sender process could be released after message has been composed and copied to sender's kernel.
2. Sender process is released after message has been transmitted to the network.
3. Sender process is released after message has been received by the receiver's kernel
4. Sender process is released after message has been received by the receiver process.
5. Sender process is released after message has been processed by the receiver and response is returned to the sender.
Send and receive primitives are said to be blocking primitives if the calling process needs to be blocked for the message delivery or receipt respectively. A nonblocking send allows the sender to carry on doing other tasks while awaiting a reply while a nonblocking receive means a server can do other tasks if no requests have arrived. Implicit in this implementation is the requirement for buffer space in the sender's and receiver's kernel due to the asynchronous operation of senders and receivers.
A number of different options (in the diagram above) could be considered when implementing the send primitive each requiring different levels of buffering.
The blocking send is typically used in client server relationships or for process synchronisation.
Request/Reply
The next logical level above point to point messaging is a service oriented request/reply style of communication. This style of communication is suited to client/server application architectures. A simple extension to the general message passing implementation could define a third primitive
reply(message)
and change the semantics of the send(dest, message) primitive to block until the reply has been received by the sender. A logical connection is established between the source and destination for the duration of the service request. The server receives the incoming request, processes it and issues a reply along the established connection. The destination for the reply does not need to be specified as it is maintained by the communication connection.
Notice that the operation of a pair of synchronous request and reply primitives is similar to the way that a procedure call operates. The caller is suspended until the procedure returns the results.
Procedure calling with parameter passing is a more convenient mechanism for a programmer than exchanging messages as it removes the responsibility for formatting and interpreting the contents of a message, i.e. a stream of bytes.
Remote Procedure Call
The objective in sending a message to a server is to have it execute a service procedure. As the server procedure is not contained within the client's address space (or host), the normal procedure calling mechanism (the runtime stack) cannot work. The invocation of a procedure in a remote process using a standard procedure call style interface at the client is known as a remote procedure call. A remote procedure call mechanism is an extension of the basic request/reply messaging service which offers a more natural interface for the programmer of client/server applications. An RPC mechanism consists of two main parts:- an Interface Definition Language and an RPC Runtime System.
RPC Interface Definition Language
The operations and associated parameters offered by a service must be made publicly available. This defines the interface to the service, i.e. the set of procedures which a client can call and the number and type of parameter values that it should pass to each procedure.
From the service definition it is possible to automatically create a group of client stub procedures, one for each service operation, which accept the corresponding parameters and package them into a message to be sent to the server. The stubs can deal with all the details of communication and receive reply messages. The reply message is unpacked and the results are returned via parameters to the client program which called the stub. The stub procedures are linked with the client program at compile time. A client program can then make a local procedure call to one of the stubs which results in a transparent remote procedure invocation at the server.
Procedures at the server are identified by a number contained in the client message. This number is specified in the interface definition. From the interface definition a server dispatch routine can be automatically generated. This routine listens for incoming messages, identifies the required operation from the message, unpacks the parameters and calls the corresponding server procedure passing it the required parameters. When the procedure completes and returns its results to the dispatcher, they are packed into a reply message and returned to the client. In this way, the server procedures are masked from the details of interprocess communication with clients and the programmer can focus on the more important function of implementing the service itself.
RPC Runtime System
Server processes can execute on arbitrary hosts with dynamically assigned communication ports. Before a client can use the service it must locate the server's communication port. A server wishing to make itself available to clients registers its name, version and communication port with an RPC directory service. The client which implements a stub interface for a particular server name and version acquires the port by contacting the RPC directory service where the server registered and by performing a search on the joint keys name and version number. RPC directory servers will operate at well known permanent ports so that they can be found.
RPC Data Format
In a heterogeneous system clients and servers may execute on different host architectures using different programming languages. The format and byte size of various standard data types may differ across these architectures. Some processors may use big-endian or little-endian formats. To enable meaningful exchange of data across heterogenous platforms some agreement must be reached on the format of the data. Either the client converts the parameters of its request to the machine format of the server, or the server converts the incoming parameters from the client to its own format. Vice versa for the reply. This approach is somewhat awkward for the application programmer. Most RPC implementations offer a standard way of representing data in an RPC environment and the job of converting from the local format to the standard format is done by automatically generated routines added to the stub procedures at each end.
RPC Stub Procedures
A stub procedure typically performs the following tasks.
Data Conversion
The local parameter formats are translated to an external standard form of data representation.
Message Construction
The normalised parameters are marshalled and packed into a message with the desired service operation number and sent to the server on a connection.
Reply and Failure Handling
Normal reply messages are unpacked and translated back to local data formats.
Reply failures can be masked by attempting a number of request retries before failing.
Note that failure of a remote procedure call due to communication failure or server crash is a semantic difference with the operation of a local procedure call and is therefore a transparency issue. This is somewhat unavoidable though as it is preferable for a client to be able to take recovery action rather than simply fail or hang indefinitely.

Case Study - Sun Solaris RPC
The Sun RPC facility consists of the following components:- rpcbind, a daemon process; rpcinfo, a command line utility; rpcgen, an interface stub generator.
Registration and Location of Service
Clients obtain the address of servers from the rpcbind daemon which executes on all machines and provides services such as Server Registration and Deregistration, a list of registered services the port address of a specified server program, the time etc. The rpcbind daemon listens at a permanent port whose number is given by machine_id.111 where machine_id is the IP address of the host running the daemon. e.g. 149.157.245.1.111 is an example port address.
Each procedure of a server is identifiable by a program number, version number and procedure number. A program number identifies a group of related procedures. A version number is included so that when a change is made to a service, i.e. to its interface, a new program number doesn't have to be reassigned to distinguish the service. Program numbers must be carefully assigned so that conflict does not occur whereas version numbers depend on the developer. Together they combine to identify the service on the machine.
Command Line Status Information
The status of the rpcbind process on any workstation may be queried with the rpcinfo utility.
Data Translation
Sun RPC uses XDR as a standard for the description and encoding of data. It fits in at the ISO presentation layer level and is roughly equivalent to the ISO standard X.409. It employs many established IEEE formats for numeric representation. It adopts the protocol of representing all items as multiples of 4 bytes with the MSB sent first. A block size of 4 bytes represents a compromise betwen making byte alignment easy across different architectures without causing data encoding to grow too large. That is, some data may not occupy all of the four byte block, leaving some of the residual padding bytes as zeroes. XDR conversion routines are automatically generated by the rpcgen utility to be used for exchanging parameters during remote procedure calls.
Interface Definition and Stub Generation
The rpcgen utility generates the client and server stub interfaces from a service definition file written in Sun's RPC specification language. This language is similar in structure and syntax to C. The rpcgen utility produces C source code for the client and server stub modules which must be compiled with the client and server code respectively. The default output of rpcgen is:
A header file of definitions common to the server and the client.
A set of XDR (External Data Representation) routines that translate each data type, used between the client and server, to a machine independent format.
A communication dispatcher for the server.
A set of communication stub procedures for the client.
Example Service Definition
The following three files define a simple client/server application. A server implements one function which is to return the local time on the machine where it runs. The client obtains the local time on its own host and then performs an RPC with the server to obtain the remote time.
The difference between local and remote times is computed and displayed by the client.
/* This file defines the interface to the timeservice "timeserver.x" */
program TIMESERVERPROG {
version TIMESERVERVERSION {
long GETTIME(void) = 1;
} = 1;
} = 0x20000019;
/* This is the server code "server.c " */
#include "timeserver.h"
long *gettime_1(req)
struct svc_req *req; /* can be used to identify the connection */
{
static long t;
/* Must be static so that when this function ends and returns a
value to the server stub, the storage still exists. */
/* get the local time on the machine where the server is running */
time(&t);
return(&t); /* Returning a pointer saves copying data to the stub */
}
/* This is the client code "client.c" */
#include <sys/types.h>
#include "timeserver.h"
void displaytime(char *s, time_t t) {
printf("%s %d:%d:%d\n", s, ((t / 3600)%24), ((t / 60) % 60), (t % 60));
}
main(int argc, char *argv[]) {
long lt, *rt; /* Local and remote times in seconds */
void *noparams; /* No arguments to be sent to server */
CLIENT *clnt; /* Used to identify a client connection with a server */
char host[20];
/* Check the command line arguments */
if (argc != 2) {
printf("Usage: %s hostname\n",argv[0]);
exit(1);
}
strcpy(host, argv[1]);
/* Get the time on this machine and display it */
time(<);
displaytime("local time is",lt);
/* Try to make a connection with the server */
clnt = clnt_create(host, TIMESERVERPROG, TIMESERVERVERSION, "visible");
if (clnt == NULL) {
printf("Couldn't contact server on host %s\n",host);
exit(1);
}
/* OK, Made a connection so call the remote funtion */
rt = gettime_1(noparams, clnt); /* This is a remote procedure call */
/* Check that we got a result */
if (rt == NULL) {
printf("Error in calling function on remote server\n");
exit(1);
}
/* Got a result so display it */
displaytime("remote time is", *rt);
printf("Difference is %d seconds\n",abs(lt-(*rt)));
}
To create the application, first create the stubs, xdr routines and common header files
rpcgen timeserver.x. Compile the server code, linking it with its stub and the networking library -
cc server.c timeserver_svc.c -o server -lnsl, then execute server on some host. Finally compile the client linking it to its stub procedures and the networking library - cc client.c timeserver_clnt.c -o client -lnsl. Execute the client giving the server's hostname as a parameter on the command line.