CS402 Parallel
and Distributed Systems
Dermot Kelly
Introduction
Parallel computing is the
simultaneous execution of the same task (split up and specially adapted)
on multiple processors in order to obtain results faster. The idea is based on
the fact that the process of solving a problem usually can be divided into
smaller tasks, which may be carried out simultaneously with some coordination.
The terms parallel processor architecture
or multiprocessing architecture are sometimes used for a computer with
more than one processor, available for processing. Systems with thousands of
such processors are known as massively parallel. The recent multicore
processors (chips with more than one processor core) such as Intel’s Pentium D,
dual core Xeon and Itanium, and AMDs dual core Opteron and Athlon 64X2 are some
commercial examples which bring parallel computing to the desktop
without having to install multiple processor chips. Current software, which is
largely written using sequential programming languages, needs to be adapted or
rewritten to make effective use of modern parallel hardware which can support
true multiprocessing within individual applications.
While a system of n parallel processors is
less efficient than one n-times-faster processor, the parallel system is
often cheaper to build. For tasks which require very large amounts of
computation, have time constraints on completion and especially for
those which can be divided into n execution threads, parallel
computation can be an excellent solution. It is often difficult however, in
programming terms, to achieve
anticipated linear speedup for applications with increased multiprocessor
support due to the interplayu of cache coherence, interprocess synchronisation
and communication problems.
Most high performance computing systems, also
known as supercomputers, have parallel architectures.
Multiprocessing is
commonly known as the use of multiple independent processors within a single
system. Tightly coupled multiprocessor systems contain multiple CPUs that
are connected at the bus level. These CPUs may have access to a central shared
memory, or may participate in a memory hierarchy with both local and shared
memory. Loosely coupled multiprocessor systems (often referred to as
clusters) are based on multiple standalone single or dual processor commodity
computers which are highly integrated via a high speed intercommunication
system (Gigabit Ethernet is common). A Linux Beowulf cluster is an example of a
loosely coupled system.
Tightly coupled systems perform better, due to
faster access to memory and intercommunication and are physically smaller and
use less power than loosely coupled systems, but historically they are more
expensive up front and don't retain their value as well. Nodes in a loosely coupled
system can live a second life as desktops upon retirement from the cluster.
A Distributed System is composed of a
collection of independent physically (and geographically) separated computers
that do not share physical memory or a clock. Each processor has its own local
memory and the processors communicate using local and wide area networks. The
nodes of a distributed system may be of heterogeneous architectures.
A Distributed Operating System attempts
to make this architecture seamless and transparent to the user to facilitate
the sharing of heterogeneous resources in an efficient, flexible and robust
manner. Its aim is to shield the user from the complexities of the architecture
and make it appear to behave like a timeshared centralized environment.
Distributed
Operating Systems offer a number of potential benefits over centralized
systems. The availability of multiple processing nodes means that load can be
shared or balanced across all processing elements with the objective of increasing throughput and resource
efficiency. Data and processes can be replicated at a number of different
sites to compensate for failure of
some nodes or to eliminate bottlenecks.
A well designed system will be able to accommodate
growth in scale by providing mechanisms for distributing control and data.
Communication is the central issue for
distributed systems as all process interaction depends on it. Exchanging
messages between different components of the system incurs delays due to data
propagation, execution of communication protocols and scheduling. Communication
delays can lead to inconsistencies
arising between different parts of the system at a given instant in time making
it difficult to gather global information for decision making and making it
difficult to distinguish between what may be a delay and what may be a failure.
Fault tolerance is an important issue for
distributed systems. Faults are more likely to occur in distributed systems
than centralized ones because of the presence of communication links and a
greater number of processing elements, any of which can fail. The system must
be capable of reinitializing itself to a state where the integrity of data and state of ongoing
computation is preserved with only some possible performance degradation.
A distributed
architecture consisting of heterogeneous hardware with the complexity problems
hinted at above is a potentially very unfriendly platform for a user. The principle of transparency is used at
many levels in the design of a distributed system to mask implementation
details and complexities from the user. This ranges from providing the ability
to access local and remote devices in a uniform way, independent of location to
automated data and process replication, load balancing and recovery.
The
goal of a distributed operating system is to provide a high-performance and
robust computing environment with the least awareness of the management and
control of distributed resources but with the flexibility to manipulate the
environment if required.
An Engineering Perspective – When is a distributed
architecture preferable over a centralised one?
You
will be familiar with the Software Development Process outlined below.
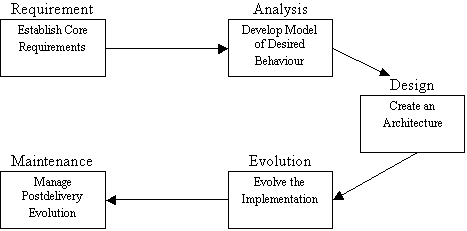
During
the requirements analysis phase of the development, a number of system
properties will be identified. These properties may be classified as functional
and non-functional components of the design.
The
functional requirements are further refined and grouped into related functions
which are then localised in particular components or modules of the system.
Non-functional
requirements are concerned with the quality of the system and are more
difficult to attribute to particular parts of the system. These requirements
are of a more global nature.
Examples
of such non-functional requirements might be Scalability of the Design, Openness
facilitating understandable and easy to use interfaces, the ability to
accommodate Heterogeneity perhaps in the hardware platform or software
language, Resource Sharing and Fault
Tolerance.
It
is the non-functional requirements of this kind which lead to the adoption of a
distributed architecture.
Remember
that centralised systems are simpler and cheaper to build, so preference should
be given to a centralised system if a distributed architecture can be avoided.
However, many of the non-functional requirements listed above cannot be
achieved properly in a centralised system.
This
course will address issues in the design of parallel and distributed systems
focusing on:-
Architectural
Models, Software System Models, Models of Synchrony
Processes
and Threads, Synchronisation and Interprocess Communication
Load
Distribution and Scheduling Algorithms
Event
Ordering and Time Services,
Atomic
Transactions, Concurrency, Recovery
Distributed
Shared Memory, File Systems, Database Systems
Fault
Tolerance
Security
Case
Studies of Parallel Programming Environments & Distributed Operating
Systems