Fault Tolerant Services
Fault tolerant services are obtainable by employing
replication of some kind. By using multiple independent server replicas each
managing replicated data it is possible to design a service which exhibits
graceful degradation during partial failure and may also improve overall server
performance.
There are two main design approaches. With Active
Replication (State Machine Approach), the service state is replicated
at all servers which are executed on separate processors. Client requests are
presented to all non faulty servers in appropriate order and there is a
mechanism for coordinating the replies. The effects of failure are masked by
voting and the resulting service is indistinguishable from a single server.
There is no centralised control. Note that there is a lot of redundant
processing and communication.
With the Passive Replication (Primary-Backup
Approach), client requests are handled by a Primary process only. If
the Primary fails, one of the Backups takes over. The Primary keeps the Backups
up to date during normal operation or else may checkpoint its state
periodically. A Backup process may have to redo some processing from the last
checkpoint state if the Primary fails. The client must be able to deal with
failures of the Primary as requests can be lost. It is a less costly scheme in
terms of redundant processing and communication and is therefore more prevalent
in practice.
Active
Replication
The state machine is a general approach to
implementing a fault-tolerant service. A state machine consists of a set of
state variables which encode its state and commands which can change its state.
Each command is executed as a deterministic program, that is, execution of the
command is indivisible with respect to other commands and modifies state
variables and/or produces output.
Clients
make requests to execute state machine commands. The request identifies the
state machine, the command and supplies parameter information required by the
command. There are many ways in which commands may be invoked, for example:- a
calling mechanism for a procedure contained in a monitor; or by passing a
message to a single threaded server process; or by generating a software
interrupt. For a general description of the state machine approach, it is
better not to specify how invocation is achieved. The defining characteristic
of a state machine is not its syntax but that it specifies a deterministic
computation that reads a stream of requests and processes each, occasionally
producing output.
An
example state machine memory is given
below:
memory: state_machine var store : array [0..n] of word read
: command(loc:0..n) send store[loc] to client end read write : command(loc:0..n,
value:word) store[loc] := value end write end memory
Requests are processed by the state machine one at a
time in an order that is consistent with potential causality which allows
clients to make the following assumptions:-
Requests issued by the same client to a given state
machine sm are processed by sm in the order they were issued.
If the fact that request r made to sm by client c could
have caused r' to be made by client c' to sm then sm processes r before r'
These assumptions do not imply that the state
machine processes requests in the order made or in the order received.
Client requests may be represented as tuples of the
form:-
<state_machine.command,
arguments>
where the invocation mechanism of the request is
ignored for generality and results may be passed back using messages. In the memory state machine example a client
might execute:-
<memory.write,
100, 16.2>
<memory.read,
100>;
<receive
v from memory>
The semantic characterisation of a state machine is
that the outputs of a state machine are
completely determined by the sequence of requests it processes, independent of
time and other system activity.
Not all collections of commands necessarily satisfy
this characterization. Consider the following process control problem in which
a client monitor process periodically
reads the value of a sensor and communicates the value to a state machine pc and delays approximately 10 seconds.
monitor : process do true ® val := sensor <pc.adjust,
val> delay D od end monitor
State machine pc
adjusts the actuator based on past adjustments saved in the variable q, the
sensor reading, and a control function F.
pc: state_machine var q : real; adjust : command(sensor_val
: real) q := F(q, sensor_val) send q to actuator end adjust end pc
We could structure the pc state machine as a single command that loops - reading from the
sensor, evaluating F and writing to the actuator. Note that this would not meet
the semantic characterisation of a state machine because values sent to the
actuator would not depend solely on the requests made to the state machine, but
would depend on execution speed and the time-varying value of the sensor. In
the example above this problem has been avoided by moving the loop into a monitor process.
In practice having to structure a system in terms of
state machines and clients does not constitute a real restriction. Anything
that can be structured in terms of procedures and procedure calls can be be
structured using state machines and clients. In fact, state machines permit
more flexibility because a client making a request is not delayed until that
request is processed and the output of the request can be sent elsewhere rather
than back to the client.
Fault Tolerant
State Machines
A component is considered faulty once its behaviour
is no longer consistent with its specification. Two representative classes of
failure are :-
Byzantine Failures: The component
exhibits arbitrary and malicious behaviour perhaps involving collusion with
other faulty components.
Failstop Failures: In response to a
failure, the component changes to a state that permits other components to
detect that a failure has occurred and then stops.
For most applications it suffices to assume Failstop
failures. However, since designs based on assumptions about the behaviour of
faulty components run the risk of failing if these assumptions are not
satisfied, it is prudent that life critical systems should tolerate Byzantine
failures as well.
A system consisting of a set of distinct components
is t-fault-tolerant if it satisfies its specification provided that no more
than t of those components become faulty during an interval of interest.
A t-fault-tolerant version of a state machine can be
implemented by running a replica of that state machine on a number of independent
processors in a distributed system. Provided each replica being run by a
non-faulty processor starts in the same initial state and executes the same
requests in the same order then each will do the same thing and produce the
same output. If we assume that each failure can affect at most one processor
then by combining the output of the state-machine replicas we can obtain the
output for a t-fault-tolerant state machine.
When processors can experience Byzantine failures,
the t-fault tolerant state machine must have at least 2t+1 replicas and the
output is produced by the majority. If processors only experience failstop
failures, then t+1 replicas will suffice and the output of the t-fault-tolerant
state machine can be the output produced by any one of its members.
The key for implementing t-fault-tolerant state
machines is to ensure that the replicas are coordinated, that is, all replicas
receive and process the same sequence of requests. This can be decomposed into
two requirements:-
Agreement: Every non-faulty state
machine replica receives every request.
Order: Every non-faulty state
machine replica processes the requests it receives in the same relative order.
Sometimes knowledge of commands can be useful
because it allows replica coordination to be weakened and cheaper protocols can
be used.
For example, Agreement can be relaxed for read-only
requests when failstop processors are being assumed. A request r, that does not
modify state variables may be satisfied by any single state machine replica.
Order can be relaxed for requests that commute. Two
requests r and r' commute in a state machine sm if the sequence of outputs and
final state of sm that would result from processing r followed by r' is the
same as would result from processing r' followed by r.
For example, the following state machine determines
the first from among a set of alternatives to receive at least MAJ votes and
sends this choice to SYSTEM. If clients cannot vote more than once and the
number of clients Cno satisfies 2MAJ > Cno then every request commutes with
every other. Thus ordered delivery would be unecessary.
On the other hand, if clients can vote more than
once or 2MAJ £ Cno then reordering the
requests might change the outcome of the election.
tally : state_machine var votes :
array[candidate] of integer init 0 cast_vote :
command(choice : candidate) votes[choice]
:= votes[choice] + 1 if
votes[choice] ³ MAJ ® send choice to SYSTEM halt elsif
votes[choice] < MAJ ® skip fi end
cast_vote end tally
Implementing Agreement
The agreement requirement can be satisfied by any
protocol that allows a designated processor, called the transmitter, to
disseminate a value to other processors in such a way that:-
All
non-faulty processors agree on the same value
If
the transmitter is non-faulty, then all non-faulty processors use its value as
the one
on
which they agree.
Protocols which establish these conditions may be
known as Byzantine Agreement Protocols, Reliable Broadcast Protocols or simply
Agreement Protocols. We have already covered reliable broadcast algorithms.
Either the client can serve as the transmitter or
the client can send its request to a single state machine replica and let the
replica execute the protocol. The hard part in designing these protocols is
coping with a transmitter that fails part way through the dissemination. If the
client is not the transmitter, it must ensure that its request is not lost or
corrupted by the transmitter before being disseminated to the other
state-machine replicas. One way to monitor such corruption is by having the
client be among the set of processes that receive the request from the
transmitter.
Implementing
Order and Stability
Order can be satisfied by assigning unique
identifiers to requests and having state machine replicas process requests
according to a total ordering relation on these unique identifiers.
A request is defined to be stable at smi once
no request from a correct client and bearing a lower unique identifier can be
subsequently delivered to state-machine replica smi.
Order is then implemented by a replica processing
the next stable request with the smallest unique identifier.
Order can be implemented using logical clocks,
synchronised real-time clocks or replica generated identifiers. We have already
looked at the basics of these schemes earlier.
Primary-Backup Fault Tolerant Architecture
An
alternative to the active replication approach is to designate one server as
the primary and all the others as backups. Clients send requests to the primary
only. If the primary fails, a service outage occurs until one of the backups
takes over. Both the active replication approach and the primary-backup
approach attempt to provide clients with the illusion of a service that is
implemented by a single server. The approaches differ in the way that failure
is handled.
With
active replication, failure is masked from the client by internal voting.
Clients see the illusion of a single non-faulty server. With primary-backup, a
request can be lost if the primary fails and so the client must be aware of the
server’s outage behaviour. Primary-backup is less costly in terms of redundant processing and so is more
prevalent in practice.
There
are three cost metrics of any primary-backup protocol.
Degree of Replication: How many servers are used
to implement the service?
Blocking Time: The worst case period
between a request and its response in any failure-free execution.
Failover Time: The worst-case period
during which requests can be lost because there is no primary.
Assuming
that no more than f components can fail, what are the smallest possible values
for these cost metrics. We need to determine the lowest theoretical bounds for
any protocol to solve the problem. We can then compare these lower bounds with real
implementations (which establish upper bounds). Ideally we want the upper and
lower bounds to be close.
Every
Primary-Backup protocol must satisfy the following properties:
PB1: Only one server can be the primary at any time and this is
agreed by all servers.
PB2: Each client maintains a single server identity to which it
sends requests.
PB3: If a client request arrives at a server that is not the
primary, it is not enqueued.
These
properties specify a protocol for client interactions. PB1-PB3 ensure that no
more than one server can enqueue each client request.
For
simplicity, assume every request requires a response to be sent. A server
outage occurs at time t in this service if some correct client sends a request
at time t to the service but does not receive a response. The server is called
a (k, D)-bofo server (bounded
outages, finitely often) if all outages can be grouped into at most k intervals
of time, with each interval lasting at most D. So even though some
requests can be lost, the number of such requests is bounded.
PB4: There exist values k and D such that the service has a
maximum of k outages with each outage having a maximum length of D.
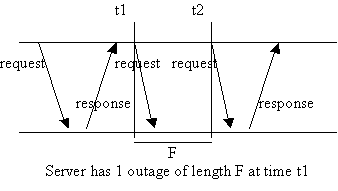
PB4
implies that primary-backup protocols can be used to implement services that
tolerate a bounded number of failures over their lifetime. A group of servers
implementing a service using primary-backup behave as a single bofo server
implementing the same service.
Sample Primary-Backup
Protocol
There
exists a primary server p1 and a backup server p2 connected by a communications
link. Assume all communication is point to point and reliable and that each
link has an upper bound of d on message delivery time.
A
client c sends a request to p1. Whenever p1 receives a request it:-
(i) Processes
the request and updates its state
(ii) Sends information about the update to p2
(iii) Without waiting for an acknowledgement from p2, sends a
response to the client.
Given
our assumptions about the comm links, this protocol guarantees that if the
client receives a response, then either p2 will receive the update or p2 will
crash.
In
addition, p1 sends out pulse messages every t seconds. If p2 does not
receive such a message for t+d seconds then p2 becomes the primary. Once p2
becomes the primary, it informs the clients and begins processing subsequent
requests.
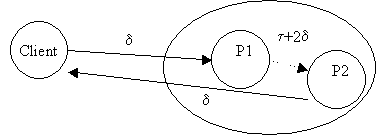
Sample Protocol Behaviour
The
service behaves as a (1,t+4d) bofo server,
k=1
as there is at most one outage with only one backup.
D= t+4d is the maximum period
during which a request may not elicit a response. This can happen as follows:
In the worst case, if p1 crashes as the client transmission arrives and
immediately after the sending of the last pulse, then p2 can take t+2d before it detects failure.
System Model
We
now generalise to a system of n servers and a set of clients to set lower
bounds on protocols that can deal with crash and link failures.
For
crash failures, assume that a processor simply stops working but does not
become byzantine.
For
link failures, assume that communication is point to point using FIFO links
that may lose messages but do not delay, duplicate or corrupt them. Messages
are enqueued at the receiving process and the queue is accessed by issuing a
receive primitive.
A
protocol tolerates f failures if it works correctly despite the failure of up
to f components.
Lower bounds
on Replication
For
crash failures, we must have n > f, where n is the number of servers, or
else we would violate PB4.
To
see the lower bounds on replication required to tolerate crash+link failures
consider the following:
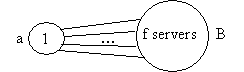 If n = f + 1
If n = f + 1
If
all servers in 'B' crash then 'a' eventually must be the primary. If the f
links between 'a' and 'B' fail, 'a' interprets this as all servers in 'B'
failing and 'B' interprets this as 'a' failing. Hence 'a' becomes primary and
some server in 'B' becomes primary violating PB1. If n > f+1, then at least
one link between 'a' and 'B' must remain non faulty.
Lower bounds
on Blocking Time
Blocking
time is the worst case elapsed time between the receipt of a request and the
sending of the associated response, in any failure-free execution assuming
computation takes no time.
Where
n > f (for crash) and n > f+1 (for crash+link) the primary can always
respond immediately because there is always one non-faulty path over which the
update will travel to the backups. So a non blocking protocol can be
implemented.
Lower bounds
on Failover Time
Failover
time is the maximum period during which requests can be lost because there is
no primary.
If
crash failures only are tolerated, then the absence of a tick from the primary
at any time lt+d (l=0,1,2,…) indicates to one
of the backups to become the primary. The minimum failover time is therefore t+d which approaches d if t is small (i.e. the ticks are frequent).
If
the new backup crashes before it sends a tick, the failover time is then » 2d. In general, for the worst
case of f failures in a row, the failover time » fd.
If
crash+link failures are tolerated, the backups must consult before deciding to
become the primary. As this involves at least one message transmission each
failure has a lower bound of 2d before a primary can exist.
If f failures occur then the minimum failover time for the service can be 2fd.

Upper Bounds
Assuming only crash
failures, an implementation which matches the lower bounds is possible:
Use ticks every lt
Primary receives request, send update to backups, don't
wait for acks before sending response to client.
Backups take over in predefined order in absence of tick
Note
that the protocol requires f+1 servers, it is non blocking and the failover
time is f(d+t). As these match the
lower bounds, no significant improvement can be made.
Assuming
crash+link failures, an implementation which matches the lower bounds is
possible:
Modify the crash tolerating protocol so that all backups
forward the primary's tick to all other backups.
The
protocol requires f+2 servers, is non blocking and the failover time is f(2d+t). These also match the lower bounds.